|
Ilya Porublyov
e-mail: ilya@cdu.edu.ua
В последнее время приобрела популярность головоломка "Японский кроссворд",
(известная также под названием ''Paint by Numbers'' --- рисование по номерам).
Решением японского кроссворда есть картинка, заданная "в монохромном
.BMP-формате": прямоугольник поделен на клеточки, и каждая из этих
клеточек или зарисована, или нет.
Входными данными для головоломки являются описания строк и столбиков этого
прямоугольника, заданные в виде последовательностей длин зарисованных блоков.
Например, если строка или столбик описан единственным
числом 3, это означает, что в этой строке (или столбике)
зарисованы в точности три клеточки, которые идут подряд (единым
блоком ); если строка или столбик заданы последовательностью
2 5 3, это означает, что в этой строке или столбике есть последовательно
две подряд, пять подряд и три подряд зарисованных клеточки, причем
блоки длиной 2, 5 и 3 идут именно в таком порядке (считая слева направо
для строк или сверху вниз для столбиков), а между разными блоками есть
по меньшей мере одна незарисованная клеточка.
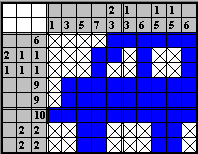
Рис. 1: Пример решенного простого японского кроссворда
Нужно написать программу, которая решает японские кроссворды.
Входные данные задаются в текстовом файле japan.dat в виде:
первая строка содержит число YSz -- количество строк в
прямоугольнике, дальше идут YSz строк входного файла, каждая из
которых содержит описание одной соответствующей строки прямоугольника.
Каждое такое описание имеет формат: сначала идет число Ni -- количество блоков в
соответствующей строке таблицы, дальше в той же строке файла Ni чисел --
длины блоков. В следующей строке входного файла
записано число XSz -- количество столбиков в прямоугольнике,
следующие XSz строк содержат описания столбиков таблицы в таком же
формате, как описания строк.
Входные данные гарантированно отвечают описанному формату в том смысле,
что записаны лишь натуральные числа, количества строк и столбиков отвечают
указанным значениям YSz и XSz, в каждом описании строки или столбика
количество длин блоков отвечает указанному числу Ni, все блоки
гарантированно могут поместиться в строке или столбике. Но неизвестно,
отвечает ли это описание качественному японскому кроссворду, где решение существует
и единственно.
Решение нужно вывести в текстовый файл japan.sol .
Картинки надо представить в виде YSz строк (длиной XSz
символов каждая), зарисованные клеточки обозначаются символом '' * ''
(звездочка), не зарисованные --- '' . '' (точка).
Если заданному на входе описания отвечают несколько разных картинок, нужно
вывести их все. После (каждого) решения нужно вывести или строку
<end> (если решение последнее) или строку <next> (если
не последнее). В случае, если заданное описание вообще не отвечает
никакой картинке, в файл нужно вывести единственную строку <no solutions>.
Примеры входных данных и результатов:
8 ....******
1 6 ...**.*..*
3 2 1 1 ...*..*..*
3 1 1 1 .*********
1 9 .*********
1 9 **********
1 10 ..**...**.
2 2 2 ..**...**.
2 2 2 <end>
10
1 1
1 3
1 5
1 7
2 2 3
2 1 3
1 6
2 1 5
2 1 5
1 6
2 *.
1 1 .*
1 1 <next>
2 .*
1 1 *.
1 1 <end>
Данная задача не является типично олимпиадной ---
едва ли кто-то сможет за несколько часов написать полное, правильное и
эффективное ее решение. Она
предлагалась на IV всемирной олимпиаде (1992 год), но
с техническими ограничениями
1 <= XSz , YSz <= 8 и потому могла быть решена гораздо менее
оптимальным алгоритмом, чем приведенный здесь.
Оценим стоимость полного перебора всех возможных
размещений зарисованных клеточек с дальнейшей проверкой соответствия
заданному на входе описанию. Например, для простенького кроссворда
с "машинкой" имеем 80 клеточек, из них 49 закрашенные.
Количество размещений
C8049 \approx 1.5* 1023,
что для современных ПЭВМ означает время выполнения,
приблизительно равное геологическому возрасту Земли.
Безусловно, значительную пользу может
принести использование принципа «отбрасывать не отдельные размещения, а большие
совокупности размещений». В частности, можно строить картинку последовательно по
строкам: пробуя разместить зарисованные клеточки в первой строке, сразу
проверять их на соответствие описанию первой строки, и переходить к попыткам
размещение клеточек второй строки лишь тогда, когда найден один из
удовлетворительных способов размещения в первой, к попыткам размещения в третьей ---
лишь тогда, если найдено удовлетворительное размещение первой и второй и так далее
до последней. Удовлетворительных размещений зарисованных клеточек в отдельной строке
может быть много, и (как правило) лишь одно из них приводит к правильно
разгаданному кроссворду; то есть, найдя допустимое размещение клеточек в
первой строке и рассмотрев все возможные размещения в следующих, нужно
возвратиться к первой строке, попробовать найти другое допустимое размещение
клеточек и снова рассмотреть все возможные размещения в следующих строках.
То есть, получается алгоритм с возвращениями (back-tracking).
Одного лишь ограничения «как можно раньше проверять строки»
достаточно, чтобы
разгадать небольшую ранее приведенную картинку с "машинкой"
(для нее имеем 17 млн вариантов,
которые ПЭВМ может просмотреть за несколько секунд), но если делать так при
разгадывании «нормального» японского кроссворда, то это все еще будет
астрономически долго.
Мы имеем две совокупности ограничений: описания строк и описания
столбиков. Руководствуясь тем самым принципом «отсечь как можно больше
и как можно раньше», следует по ходу построения картинки по строкам проверять
еще и соответствие построенной части картинки ограничением по столбикам
(еще не достроив эти столбики до низа).
Попытка реализовать алгоритм такого вида привела к более удовлетворительным
результатам: из около 80 японских
кроссвордов размерами от 20*20 до 30*30 около 70 были
разгаданы за несколько секунд работы программы, для нескольких других время
разгадывания составило от минуты до нескольких часов, а несколько штук так и
не были решены за сутки.
И все-таки, использование одних только общих алгоритмических подходов
не дало действительно хорошего результата. Поэтому, опишем на примере
все того же японского
кроссворда с "машинкой" некоторые приемы ручного разгадывания.
Картинка состоит из 10 столбиков, и 6-й строка содержит блок
длиной 10. Очевидно, что в этой строке зарисованы все клеточки.
4-й и 5-й строки содержат (каждая) блок длиной 9, а общее количество
столбиков 10, и мы не можем указать точного размещения этого блока; но
оба возможные (то есть все возможные ) размещения блока
(клеточки или с 1-ой по 9-ую, или со 2-ой по 10-ую) имеют общее
свойство, что клеточки со 2-ой по 9-тую зарисованы. То есть, мы (еще)
не знаем правильного вида всей строки, но знаем абсолютно точно,
что эти клеточки зарисованы. Аналогичным образом можно зарисовать
отдельные клеточки в 4-ом, 7-ом и 10-ом столбиках. После
этого уже можно начать использовать сделанные раньше выводы.
Так, в 1-ом столбике есть единый блок длиной 1, и имеем одну зарисованную
клеточку. Итак, она и есть этим блоком, а остальные клеточки гарантированно
не зарисованы. Ситуация с блоком длиной 3 во 2-ом столбике совершенно
аналогичная. В 3-ем столбике мы (еще) не можем определить точного положения
зарисованного блока, но он единственный и имеет длину 5, а 6-ая
клеточка столбика зарисована, поэтому 1-ая клеточка не может
быть зарисованной. В 1-ой строке есть единственный блок длиной 6, и мы выяснили,
что 1-ая, 2-ая и 3-ья клеточки строки гарантирован не зарисованы --- стало быть,
блок должен втиснуться в диапазон от 4-ой по 10-тую клеточки и поэтому клеточки
с 5-ой по 9-ую зарисованы; ...
Мы не будем продолжать ручное решение, так как, увлекшись рассмотрением
мелочей, можно «за деревьями не увидеть леса».
Частое повторение некоторых словосочетаний делает целесообразным
введение специальной
терминологии. Так, столбики и строки (и лишь они) будут
носить общее имя линия; столбик и столбик, или строка и строка
будем называть линиями одного типа, столбик и строка ---
линиями разного типа. Будем также говорить, что каждая клеточка может
находиться в одном из трех состояний: зарисованная, гарантированно
не зарисованная, или такая, о которой мы еще ничего не знаем.
Состояния «зарисованная» и «не зарисованная» есть окончательными, а состояние «пока что неизвестно»
неокончательно и в процессе решения будет изменено на какое-либо
из двух других.
Попробуем выделить в приведенных приемах общие идеи, пригодные для
алгоритмизации.
-
По последовательности длин блоков в отдельности взятой линии (как правило)
нельзя однозначно определить окончательные состояния всех клеточек этой линии, но
анализ такого описания может дать ответ относительно окончательных состояний
некоторых клеточек.
-
Чтобы начать решать японский
кроссворд таким способом, необходимо иметь линии, в которых можно найти некоторые
окончательные состояния клеточек, опираясь лишь на последовательность длин
блоков этой линии.
-
Для продолжения решения
дополнительно могут быть использованные некоторые линии, в которых на
предшествующих шагах найдены окончательные состояния клеточек.
-
Линии, которые не могут быть использованы
согласно пункту 2, становятся пригодными к использованию
согласно пункту 3 лишь при условии, что эти
окончательные состояния найдены на предшествующих шагах не за счет анализа
этой же линии, то есть за счет анализа линии другого типа,
проходящей через эту клеточку.
Итак, этот способ решения японского кроссворда требует последовательного
анализа отдельных его линий.
В программе целесообразно иметь представление всей картинки японского кроссворда (на
текущем «уровне разгаданности») в виде двумерного массива
pict[1..MAXY,1..MAXX] of byte, где значения элементов
будут отвечать текущему состоянию клеточек: 1 -- зарисованная, 0 --
гарантированно не зарисованная, 2 -- пока что неизвестно. Может возникнуть
желание реализовать анализ строк и анализ столбиков в отдельности (разные
продедуры AnalyzeRow(row:byte) и AnalyzeColumn(col:byte) )
--- в таком случае эти подпрограммы могли бы работать непосредственно с массивом
pict. Но это означало бы, что нужно два раза реализовать очень
похожий и вместе с тем заметно разный программный код. Такой подход имеет то
преимущество, что можно добиться некоторого повышения эффективности программы, но
он имеет по меньшей мере два недостатка. Меньший из них состоит в том, что возрастает
объем программного кода; другой (очень существенный в данной ситуации) недостаток ---
недостаточная аккуратность при программировании таких «параллельных» фрагментов
программы приводит к несогласованиям, являющимся источником неприятных
ошибок, которые очень тяжело отлаживать. Поэтому, будем иметь дело
с единой для всех линий подпрограммой, а учитывать, какую именно линию обрабатываем, будем лишь на внешнем
относительно этой подпрограммы уровне.
Нужно выяснить, какой анализ линий надо проводить. Сказать
«приблизительно такой, как приведен выше
относительно кроссворда с "машинкой" » ---
не сказать ничего конкретного, так как эти соображения являются частными случаями
и далеко не исчерпывают всех возможностей анализа линии. В частности, там
отсутствуюет мощный пласт приемов для анализа ситуации, когда в строке
есть несколько блоков довольно большой длины.
Может возникнуть желание сесть и выписать по возможности большее количество разных
приемов, а потом их все запрограммировать. Но здесь есть по меньшей мере две проблемы.
Во-первых, подобная работа требует большой аккуратности, и выполнить
ее без ошибок почти нереально. Во-вторых, какую бы совокупность отдельных приемов
мы не разработали, мы никогда не будем уверены, что их достаточно, чтобы сделать
самый результативный анализ любой линии.
Осознав эти проблемы, хочется вспомнить, что разгадывание японского
кроссворда считают интеллектуальным развлечением, и напрашивается
вывод, что куда нам его программировать. И все же не следует на самом лишь
основании «интеллектуальности» считать, будто программа должна быть беспредельно
сложная. Если нужно запрограммировать задачу, которую считают
интеллектуальной, когда ее выполняет человек, способы решения этой задачи
человеком необходимо изучить, но не нужно слепо их копировать --- не
исключено, что «интеллектуальность» на самом деле означает только
сложность для человека.
Не придумав ничего лучшего, разработаем для анализа отдельной линии
как можно более оптимизированный перебор.
Легко видеть, что не следует заниматься перебиранием отдельных клеточек.
Намного эффективнее работать с блоками как едиными целыми.
В частности, если в линии есть лишь один блок, то перебор вариантов размещений
блоков будет состоять просто из L-B1+1 попыток поставить начало блока в
1-ую, 2-ую, ... , (L-B1+1)-ую клеточки линии (где L -- общее
количество клеточек в линии, B1 -- количество клеточек в блоке).
Для каждого из этих вариантов нужно проверить, не противоречит ли он уже
известным окончательным состояниям клеточек. Говоря, что вариант размещения
противоречит известным окончательным состояниям, мы имеем в виду
примерно следующее: если из предшествующего анализа мы знаем, что 5-ая клеточка линии
имеет окончательное состояние «не зарисована», то размещать блок длиной 4
в клеточках с 3-ей по 6-ую нельзя, так как это будет противоречить ранее
найденному состоянию 5-ой клеточки. То есть, противоречивость варианта размещения
блоков с окончательными состояниями появляется или когда пробуем разместить блок
поверх гарантированно не зарисованной клеточки, или «симметричным» образом,
когда какая-то клеточка имеет окончательное состояние «зарисованная» и оказывается
в промежутке между блоками.
Вспомним, как мы аргументировали
правильность зарисовывания клеточек в 4-ой и 5-ой строках
кроссворда с "машинкой": «все возможные размещения
имеют общее свойство , что клеточки ... ». Именно этим мы и будем
заниматься: искать свойства, общие для всех размещений блоков
в линии, не противоречащих уже найденным окончательным состояниям.
Будем поддерживать булевские массивы can_one и can_zero:
элементы can_one будут соответствовать утверждению «клеточка такая-то
может быть зарисованной», элементы can_zero --- «клеточка такая-то
может быть не зарисованной». Перед началом анализа линии все элементы обоих
массивов нужно инициализировать значением false; каждый раз, найдя
непротиворечивое размещение блоков, нужно для клеточек, попавших
в блоки, установить в true соответствующий элемент can_one,
для попавших в промежутки между блоками --- элемент can_zero.
Завершив рассмотрение вариантов размещение блоков, нужно проанализировать
полученные значения элементов массивов can_one и can_zero:
-
Если для какой-то i-ой клеточки линии оба значения
can_one[i] и can_zero[i] истинные, то она может быть
как зарисованной, так и не зарисованной, и мы не узнали о ней
ничего нового.
- Если (вдруг...) для какой-то клеточки оба значения
can_one[i] и can_zero[i] ложные, то она не может быть
ни зарисованной, ни не зарисованной, то есть имеем неправильные входные данные,
не соответствующие никакой картинке.
- Если для какой-то клеточки, которая до сих пор имела состояние «неизвестно»,
в точности одно из значений can_zero[i] и can_one[i]
истинно, то мы выяснили окончательное состояние этой клеточки.
Рассмотрим вопрос «как организовать просмотр
непротиворечивых размещений и нахождения общих для них свойств
в случае линии с несколькими блоками» .
Пусть мы анализируем линию из L клеточек, которая содержит N блоков, длины
блоков хранятся в массиве bl_len, состояния клеточек блока (в том
самом кодировании 1 -- зарисованная, 0 -- свободная, 2 -- неизвестно) --- в массиве
cells. Это --- все параметры, которые
нужны для анализа линии.
Все возможные (включая противоречивые) размещения блоков состоят из: тех,
где 1-ый блок начинается в 1-ой клеточке, а следующие розмещены где-то после
него; тех, где 1-ый блок начинается во 2-ой клеточке, а следующие розмещены
где-то после него; и т.д. Таким образом, задачу «просмотреть
размещение всех блоков» можно свести к «перебрать все
возможные размещения 1-ого блока, причем для каждого из таких размещений
просмотреть (тем же способом) размещение всех следующих после него
блоков». То есть, имеем рекурсивный процесс: переход к следующему в линии
блоку --- рекурсивный вызов, рассмотрение последнего в линии блока --- выход
из рекурсии.
Параметрами рекурсивного вызова могут быть theblock (номер
блока) и thestart (клеточка, в которой мы пробуем разместить
начало этого блока). Сначала нужно проверить, что сам блок разместился
непротиворечиво (для всех i от thestart
до thestart+bl_len[theblock]-1 имеем
cells[i]<>0); если это так и блок не последний в
линии (theblock<N), то нужно просмотреть размещения
следующих, то есть выполнить рекурсивные вызовы для возможных мест начала
следующего блока. Поскольку он следующий, 1) он должен начинаться
не раньше, чем через одну клеточку после конца текущего; 2) необходимо, чтобы
ни одна из клеточек между концом текущего блока и началом следующего не была
окончательно зарисованная (то есть для всех клеточек промежутка
cells[i]<>1). Если блок последний, нужно, чтобы
ни одна из клеточек после него не была окончательно зарисована (для всех i
от thestart+bl_len[theblock] до L должно быть cells[i]<>1).
procedure TryBlock(theblock,thestart:shortint);
var i,startnext:shortint;
Begin
for i:=thestart to thestart+bl_len[the_block]-1 do
if cells[i]=0 then exit;
if theblock<N then begin
for startnext:=thestart+bl_len[theblock]+1 to
L-bl_len[theblock+1]+1 do begin
if cells[startnext-1]=1 then break;
TryBlock(theblock+1,startnext)
end;
end else begin
for i:=thestart+bl_len[theblock] to L do
if cells[i]=1 then exit;
(*Каждый раз, дойдя сюда, имеем новое непротиворечивое размещение блоков*)
end
End;
Вот первая попытка реализации рекурсивной подпрограммы TryBlock. Массивы cells, bl_len,
can_one, can_zero и переменные N, L описаны во
внешнем относительно TryBlock блоке
программы. Реализация полностью отвечает только что приведенным соображениям,
с очевидным дополнением (запуская TryBlock, нужно позаботиться,
чтобы блок не вышел за пределы линии, отсюда верхнее ограничение соответствующего
цикла for ), и небольшой оптимизацией (если между концом текущего
блока и началом следующего, где должно быть свободное место, есть клеточка
(cells[i]=1), то эта же проблема будет и для всех
дальнейших размещений следующего блока, поэтому цикл можно оборвать).
Эта первая пробная реализация есть «вещью в себе»: она
перебирает непротиворечивые размещения блоков, но (пока что) не делает с ними
ничего полезного. Основная полезная нагрузка, которую нужно туда прибавить
--- по мере просмотра вариантов непротиворечивых размещений устанавливать
значение соответствующих элементов can_one и can_zero.
Если бы мы исходили из того, что нужно строить все возможные непротиворечивые
размещения всех N блоков, то действия по работе с can_one
и can_zero надо было бы поместить на место комментария.
Для этого пришлось бы использовать
еще какой-либо глобальный массив, так как наша реализация, рассматривая последний блок
линии в глубочайшем рекурсивном вызове, не имеет легкого доступа
к размещениям предшествующих блоков. Но лучше, если мы сумеем
вынести процесс
заполнения значений элементов can_one и can_zero на те вызовы
TryBlock, где размещение соответствующего блока хранится просто
в параметре thestart.
В самом деле, процедура TryBlock делает
несколько рекурсивных вызовов, поэтому глубочайших вызовов
(theblock=N) будет очень много, возможно больше чем всех других
вместе взятых. Значит, сокращение работы на глубочайшем уровне
рекурсивной вложенности (устанавливаем значения элементов can_one
и can_zero не для всей линии, а лишь для части, которая касается
последнего блока) должно привести к уменьшению общего объема работы.
Решающующим является такое наблюдение:
Чтобы установить элемент can_one в true,
достаточно знать, что существует какое-то непротиворечивое
размещение блоков, при котором эта клеточка попадает в блок; знать
же конкретный вид такого размещения не обязательно.
Вызовы TryBlock для следующего блока происходят тогда, когда
найдено непротиворечивое размещение текущего; поэтому, на момент вызова
TryBlock с параметрами theblock и thestart
клеточки линии с 1-ой по ( thestart-1 )-ю не создают
противоречий; в случае успешной проверки в первом for 'е клеточки
самого блока theblock также свободны от противоречий; значит,
остается выяснить только возможность непротиворечивого размещения
следующих блоков. Более глубокие по вложенности вызовы
почти это и делают. Итак, модифицируем подпрограмму так, чтобы функция
TryBlock возвращала значение типа
boolean, смысл которого -- «можно ли, разместив начало
блока theblock в клеточке thestart, получить какое-то
непротиворечивое размещение всех блоков от theblock по L-ый».
Проверка непротиворечивости размещения самого блока theblock и
проверка конца линии в случае theblock =N остается в точности
такой же, как в первой реализации, лишь
делается дополнение, что найдя противоречие нужно
возвратить false, а благополучно дойдя до конца линии, можно
возвратить true. Учет результатов дальнейших рекурсивных
вызовов в случае theblock<N требует дополнительной переменной, так как
какое-то размещение существует тогда, если оно существует
хотя бы для одного варианта размещения следующего блока.
function TryBlock(theblock,thestart:shortint):boolean;
var i,startnext:shortint;
res:boolean;
Begin
for i:=thestart to thestart+bl_len[theblock]-1 do
if cells[i]=0 then begin TryBlock:=false; exit end;
if theblock<N then begin
res:=false;
for startnext:=thestart+bl_len[theblock]+1 to
L-bl_len[theblock+1]+1 do begin
if cells[startnext-1]=1 then break;
if TryBlock(theblock+1,startnext) then begin
res:=true;
(*какое-то непротиворечивое размещение дальнейших блоков существует*)
end;
end;
TryBlock:=res
end else begin (* theblock = N *)
for i:=thestart+bl_len[theblock] to L do
if cells[i]=1 then begin TryBlock:=false; exit end;
(*данное размещение последнего блока непротиворечиво*)
TryBlock:=true
end
End;
Таким образом получаем вторую версию рекурсивного просмотра непротиворечивых
размещений блоков в линии.
Теперь уже можно включать в нее
заполнение элементов can_one и can_zero для части линии,
соответствующей положению текущего блока. Эти заполнения нужно включить
в места, обозначенные в только что приведенном фрагменте комментариями
(результат см. в окончательном тексте программы).
Мы уже довольно давно обсуждаем построение подпрограммы TryBlock, но еще
ни разу не сказали, как мы собираемся обращаться к ней. Логично
считать, что это должны быть несколько вызовов с параметром
theblock=1, в которых параметр thestart
изменяется от 1 до, например, L-bl_len[theblock]+1. Но
в таком случае приходим к необходимости дублировать работу, которую
выполняет сама TryBlock в случае theblock<N.
Это касается как перебора возможных мест начала блока, так и заполнения
элементов can_zero, которые касаются клеточек от 1-ой
по thestart -1. Такого дублирования фрагментов программного кода
можно избегнуть, введя к рассмотрению дополнительный «виртуальный» блок номер 0,
имеющий длину 1 и размещенный строго в (-1)-ой клеточке линии --- тогда
можно обойтись единственным вызовом TryBlock(0,-1).
Выполнение вызова TryBlock(theblock,thestart) не зависит
от того, какие были параметры вызовов на более внешних уровнях рекурсии,
поэтому разные вызовы с одними и теми же параметрами должны приводить
к абсолютно одинаковым последствиям (где под последствиями понимаются и значение,
возвращаемое функцией, и присвоение значений элементам массивов
can_one и can_zero). Разных вызовов с одинаковыми параметрами
может быть очень много, особенно если в линии много коротких блоков
и мало клеточек с известными окончательными состояниями и потому
почти не срабатывают отсечения по несовместимости. То есть, имеем большое
перекрытие подзадач и использование memoized
recursion означает очень существенное повышение эффективности.
Правда,
если функция TryBlock возвращает значение ''да'' или ''нет'',
то в элементах таблицы решенных задач надо сохранять одно из
трех значений («ответ ''да''», «ответ ''нет''» или
«данная подзадача еще не решалась»), и потому нужно переходить от
типа boolean к shortint.
На этом мы завершаем вопрос об анализе линии и переходим к тому, как это
все применить к решению японского кроссворда в целом.
Поскольку мы захотели иметь одну универсальную подпрограмму, которая рассматривает
любые линии, необходимо реализовать некоторый интерфейс: перед началом
анализа линии превратить нужную строку или столбик двумерного массива
pict в массив клеточек линии cells, а после завершения
анализа линии --- внести его результаты в pict.
При этом нужно передавать тип линии (строка или столбик)
как параметр. Поскольку типов линий есть в точности два и нам часто нужно
иметь дело с «линией другого типа, чем данная», для представления
удобно пользоваться переменными типа boolean, например
true означает «строка», false --- «столбик»: если тип
данной линии подается в переменной whatline, то получить тип «линии
другого типа» можно просто как not whatline.
Преобразование строки или столбика pict в массив cells
довольно понятно; вопрос же об использовании результатов анализа требует
некоторых пояснений.
Вследствие выполнения вызова TryBlock(0,-1) получаем результат
(''да'' ли ''нет'') и новое содержимое массивов can_one и can_zero.
Смысл возможных комбинаций значений элементов этих массивов описан
выше
(правда, наличие результата вызова TryBlock(0,-1) делает
ненужной проверку на одновременную ложность can_one[i]
и can_zero[i] ): каждый раз, когда имеем
can_one[i] xor can_zero[i]
(истинный в точности один из этих элементов), мы нашли новое окончательное
состояние. Понятно, что это нужно запомнить в соответствующем элементе массива
pict; но нужно также выполнить еще некоторые действия.
Как указано ранее, результативность анализа линии
может повыситься тогда, когда некоторые из ее клеточек получили окончательные состояния
вследствие анализа линии другого типа. Итак, если мы в резутате анализа
can_one и can_zero находим окончательное состояние для какой-то
i-ой клеточки линии, i-ая линия другого типа становится «более
обнадеживающей» для анализа.
Может возникнуть желание учесть это следующим образом: занеся
соответствующее значение (0 или 1 вместо 2) в соответствующий элемент массива
pict, сейчас же запустить (рекурсивно) анализ этой i-ой линии
другого типа. Такое решение будет правильным (при условии, что массивы
can_one и can_zero --- локальные переменные), но очень
нецелесообразным.
В процессе таких рекурсивных вызовов, как правило, рекурсия
будет довольно сильно «тянуться вглубь» (например, проанализировав
2-ую строку нашли новое окончательное состояние для 4-ого столбика,
проанализировав 4-ый столбик нашли новое окончательное состояние для 7-ой
строки, проанализировав 7-ую строку нашли новое окончательное состояние для 3-его
столбика, проанализировав 3-ий столбик нашли новое окончательное состояние
опять-таки для 2-ой строки, и т.д.). Это создает по меньшей мере две проблемы.
Пусть вследствие анализа линии в массивах can_one и can_zero
образовались такие значения, по которым можно определить окончательные состояния
для нескольких
клеточек. Если мы сделаем рекурсивный вызов немедленно после того,
как модифицируем соответствующий элемент массива pict лишь для первой
из них, все это большое количество вызовов не будет иметь возможности воспользоваться уже
полученными окончательными состояниями, а значит (возможно) будет делать лишнюю работу.
Поэтому целесообразно сначала пройти линию с начала до конца, анализируя
полученные значения can_one и can_zero и соответственно
модифицируя элементы pict, а уже потом начинать анализировать другие
линии. Но тогда появляется сомнение, действительно ли рекурсия ---
самое удобное средство реализации такого алгоритма.
Другая проблема (сугубо техническая,
но очень важная при программировании в Turbo Pascal) ---
переполнение стека. Наибольшая глубина таких рекурсивных вызовов может
достигнуть XSz*YSz, ведь мы гарантированы от того, чтобы «пойти
и не возвратиться», то есть от бесконечных рекурсивных вызовов, но
исключительно за счет того, что перед каждым вызовом значения какого-то
элемента pict изменяется с 2 на 0 или 1, а количество таких
элементов --- XSz*YSz.
Не придумав ничего лучшего, будем действовать просто. Каждая линия может быть
или такой, что ее анализ еще не проводился, или такой, что для нее
провели анализ, и потому следующий анализ не даст ничего нового, или такой,
что в ней найдены новые окончательные состояния клеточек за счет анализа линий
другого типа, и потому новый анализ может быть более результативным, чем предшествующий.
Из этих трех состояний нам удобно различать два: анализ данной линии может быть
результативным или анализ данной линии не может быть результативной. Поэтому,
будем поддерживать массив need_refresh (размерами
false..true \times 1..MAXSZ , где первый индекс означает тип
линии, второй --- ее номер), элементы которого будут истинными, если анализ
соответствующей линии может быть результативным. В начале для всех линий
нужно выставить значения true, проанализировав какую-то линию,
выставить ей самой значение false, а тем линиям другого типа,
в пересечении с которыми найдены новые окончательные состояния --- значение
true. Теперь применять анализ к, например, строкам можно
просто в цикле for i:=1 to YSz do if
need_refresh[true,i] then ... .
Все это повторение реализовано в процедуре IterateLineLook.
Повторять просмотр всех строк и всех столбиков, где анализ может
результативным, нужно
многократно, поэтому эти циклы окружены циклом repeat ... until.
Но нужно гарантировать, что этот внешний цикл не будет крутиться
бесконечно. Смысл переменной sl, контролирующей выход из цикла
repeat, -- «хотя бы одна строка была проанализированная». Возможно,
такое условие не наилучшее, но оно простое и правильное.
Каждый анализ линии может или привести к нахождению окончательного состояния для
новой клеточки, или не привести. Найти новое окончательное состояние
можно не большее чем XSz*YSz раз; вызовов, не приводящих к
нахождению нового окончательного состояния, тоже конечное количество, так как вследствие
каждого такого вызова уменьшается количество значений true в
массиве need_refresh.
Техническое замечание. Мы сделали рекурсивную функцию
TryBlock локальной функцией
процедуры AnalyzeLine. Такая возможность есть не во всех языках
программирование (например, ее нет в C/C++). Более того, часто считают,
что этой возможностью лучшее вообще не пользоваться. Мы согласны с тем,
что не следует ею злоупотреблять, но сейчас имеем один из случаев, когда
применение такой конструкции оправдано.
Функция TryBlock нужна лишь внутри AnalyzeLine;
для рекурсивных функций каждый лишний параметр означает существенные лишние
затраты программного стека и потому приходится работать по возможности с
глобальными переменными. Объявление же фунции локальной разрешает сделать некоторые
переменные (N, L, bl_len, ...) внешними относительно
TryBlock и вместе с тем не делать их общедоступными всей
программе.
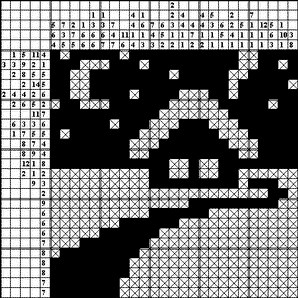
Рис. 2: Японский кроссворд "зима", который имеет единственное решение,
но не может быть решен использованием лишь итерированного анализа линий
Рассмотренного до сих пор материала достаточно, чтобы реализовать такую программу
решения японского кроссворда: прочитать входные данные, прокрутить анализ
линий в процедуре IterateLineLook, вывести содержимое массива
pict как результат. Будем называть такой алгоритм
итерированным анализом линий. Во многих случаях он действительно будет
решать японский кроссворд, но не всегда. Итерированный анализ линий по
самой своей природе (он детерминированный и не содержит перебора) может
решить лишь «качественный» японский кроссворд, который имеет единственное
решение, а программа в случае потребности может находить все решения.
Более того, только что приведен японский кроссворд "зима",
имеющий единственное решение, который такой алгоритм не сможет решить:
*.*****.***********..****
***...***.*********..**.*
**..********.*****..*****
**..**************.*****.
**..****.****...**.******
.**...******.....*****.**
***********.......*******
******.***...***...******
*.*******...*****...*****
********..??*****??..****
********..*********..****
************..*..********
..........**..*..**......
.........??*******???*??.
???????.????.....????.??.
????????????????????????.
????????????????????????.
????????????????????????.
.????**????..............
.??*****??...............
?????***?????............
????????????????????????.
????????????????????????.
????????????????????????.
????????????????????????.
Во всех упомянутых случаях итерированный анализ линий завершит просмотры,
имея в некоторых элементах массива pict двойки (состояния клеточек
«еще не известно»; на рисунке показаны знаками '' ? '').
Поскольку нужно в случае необходимости находить все решения,
приходим к необходимости делать перебор. Этот перебор будет запускаться
только в случаях, когда итерированный анализ линий оставил невыясненными
состояния некоторых клеточек.
Перебор состоит в том, что найдя клеточку с невыясненным состоянием,
сначала предполагаем, что она не зарисованная, и смотрим что из этого получится,
потом предполагаем, что зарисованная, и смотрим что получится.
Если мы предположили, что клеточка имеет такое-то окончательное состояние, по той строке
и потому столбику, к которым она принадлежит, увеличилось количество ограничений,
и из этого (возможно) будут следовать окончательные состояния других
клеточек; из тех окончательных состояний могут следовать еще какие-то новые окончательные
состояния, и так далее. То есть, чтобы «посмотреть, что получится», целесообразно
использовать итерированный анализ линий.
Будем говорить, что итерированный анализ линий, который делается в самом
начале --- первичный анализ, а проверяющий следствия
предположения --- анализ предположения.
До сих пор мы рассматривали принципиальную возможность, что при анализе какой-то
линии TryBlock(0,-1) возвратит ''нет'', но считали, что это будет в
исключительных
ситуациях, когда заданным на входе данным не соответствует никакая картинка.
Теперь, когда итерированный анализ линий используется также для выяснения
результатов сделанного предположения, эта ситуация становится намного более реальной и
может означать просто неправильность сделанного предположения. Например,
так и будет при решении японского кроссворда "зима":
предположение pict[10,11]=0 приводит к
нахождению (единственного) решения, а предположение pict[10,11]=1 ---
к противоречию.
Результаты анализа предположения не единственно правильные, как результаты
первичного анализа, а следствия этого предположения. Поэтому, проверять
второе предположение нужно, опираясь на результаты первичного
анализа, но ни в коем случае не на результаты анализа первого предположения.
Отличить же одни результаты от других невозможно, так как они являются одинаковыми
единичками и ноликами в одном и том же массиве pict.
Значит, прежде чем запускать анализ первого предположения, нужно сделать
копию массива pict, чтобы использовать ее для анализа второго
предположения.
Но после рассмотрения предположения тоже могут остаться
клеточки со состоянием «неизвестно» (в частности, так будет для «очень некачественных»
японских кроссвордов, которые имеют больше двух решений). В таком случае
внутри какого-то из (возможно, обоих) предположений придется делать
еще предположение относительно какой-то (другой) клеточки. По той самой причине, может
оказаться недостаточно и двух, и трех, и любого заданного заранее количества
предположений. И перед каждым анализом предположения нужно делать копию
pict.
Поскольку мы не знаем заранее количества «вложенных» предположений,
целесообразно реализовать эти предположения рекурсивной подпрограммой
Try: каждая потребность рассмотреть два предположения для клеточки
с неокончательным состоянием порождает два рекурсивные вызова Try,
нахождение окончательных состояний всех клеточек есть одним условием выхода из
рекурсии, нахождение противоречия --- другим условием выхода. Сохранение
копий pict в таком случае можно делать в локальной переменной.
Правда, при попытке объявить локальной переменной сам массив имеем большой
риск переполнения стека, поэтому (и лишь по этой причине) придется сделать
локальным указатель на область, выделенную в свободной памяти.
Описанный способ организации перебора с отсечениями с помощью
рекурсивной подпрограммы Try есть (несколько специализированным) примером
известного метода, который называется back-tracking (по-русски
или переводят как алгоритм с возвращениями, или так и пишут
бектрекинг ). Более детальные описания этого метода и многих его
надстроек приведенные в многих источниках, среди которых мы выделяем
[Шень], [Лип], [Оснпр], [Ставр], [Гухи].
Поскольку нахождение противоречия должно стать условием выхода из
подпрограммы Try, нужно уметь изнутри Try
различать ситуацию, когда случилось это противоречие, от ситуации, когда
итерированный анализ линий просто не смог найти окончательные состояния для всех
клеточек. Это можно реализовать двумя способами. Способ первый, который
подавляющее большинство алгоритмистов считает лучшим в плане совершенства,
красоты и стиля --- сделать подпрограммы анализа линии
AnalyzeLine и итерированого анализа линий IterateLineLook
функциями, которые в этих разных случаях будут возвращать разные значения
( AnalyzeLine может смотреть на то, какое значение возвратил вызов
TryBlock(0,-1), тогда IterateLineLook сможет смотреть на
то, какое значение возвратила AnalyzeLine ). Другой способ (менее
красивый, но более популярный на практике) --- завести глобальную переменную
ErrorLevel, значение которой перед началом итерированого анализа
линий будет устанавливаться в 0, а при нахождении указанного
противоречия --- в 1.
Еще один мелкий вопрос. Решения удобно выводить по мере
нахождения, а не находить все возможные, и лишь потом выводить. По условию
нужно после решения выводить строку <end> или <next>
соответственно тому, последнее оно или будут еще другие. Конечно же, в момент
когда мы только что нашли решение, мы не можем знать, последнее ли оно (кроме
тривиального случая, когда решение единственно, так как получено применением
лишь первичного итерированого анализа линий). Поэтому, порядок вывода этих
строк будет такой: после решения ничего не выводить, но
перед всеми решениями, кроме первого, выводить строку <next>
(которая касается предыдущего решения), а перед завершением
программы выводить или <end>, или <no solutions>
в зависимости от того, было ли найдено хоть одно решение.
Результат наших стараний находится в файле japan.pas.
Как читатели уже могли заметить, наша реализация не оптимальна в некотрых технических
деталях. Например, мы везде, где можно, пользовались
статическими массивами заранее заданного размера. Конечно же, в некоторых местах,
в частности задавая последовательности длин блоков в линиях, было бы более целесообразно
использовать полноценное динамическое выделение нужного объема памяти
(используя GetMem ). Кроме того, вследствие использования
больших массивов определенного заранее размера мы вынуждены были сделать их
глобальными (хотя более разумно было бы ограничить область видимости
cells, tb_res, can_one и can_zero) --- ведь
если бы мы объявили их локальными переменными, память для них выделялась бы
в дефицитной стековой памяти (program stack). ( Много конкретных
современных версий языков программирования имеют механизм статических локальных
переменных, который разработан для несколько другой цели (сохранение значение
локальной переменной между викликами подпрограммы), но целиком подходит для
решения данной проблемы )
Другой яркий пример --- мы очень долго разрабатывали функцию
TryBlock, и все же приведенный окончательный вид допускает много
мелких оптимизаций: например, верхнюю границу цикла
for startnext:= ...} можно устанавливать такой, чтобы в линию
поместился не только непосредственно следующий блок theblock+1,
а все следующие включительно с N-ым; устанавливать значение true для
элементов can_zero можно не после каждого успешного выполнения
рекурсивного вызова, а лишь после последнего успешного (где «успешный»
-- возвративший результат true ); и т.д.
Мы сделали так, как сделали, главным образом для того, чтобы хоть немного уменьшить
громоздкость изложения. Кроме того,
это дает всем желающим достаточно пространства для улучшений и оптимизаций.
Что касается ассимптотических оценок приведенного алгоритма, то в данном случае
они маловразумительны.
Итерированный анализ линий имеет сложность по времени n4*k, n -- линейный размер
поля, k -- количество блоков в линии (многократное использование динамического
программирования, реализованого через memoized recursion, каждое применение
n2*k, применений в худшем случае n2).
Итерированный анализ дает ответ часто, но не всегда, поэтому
на плохих кроссвордах приходится запускать бектрекинг.
Бектрекинг на хоть самую малость разумных кроссвордах очень редко бывает
большим, чем 4-8 вариантов. Но нет
очевидных причин утверждать, что в худшем случае глубина будет существенно
меньше n2, т.е. количествово вариантов -- 2n^2. Суммарно (сделав
примитивный амортизационный анализ, который ничего толком не меняет) --
(2(n^2))*n3*k.
Теперь об оценках памяти. В итерационном анализе памяти надо n*(n+k)
(с большим константным множителем). Бектрекинг в среднем этой оценки
не меняет, но в худшем случае оценка памяти будет n4.
Если же кто-то из читателей найдет принципиально
другой эффективный способ, просим сообщить нам.
|