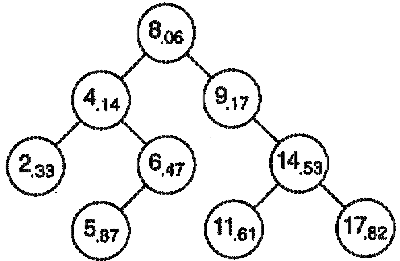
При вводе элемента в дерево случайного поиска этому элементу приcваивается приоритет — некоторое вещественное число с равномерным распределением в диапазоне [0, 1] (вероятность выбора любого числа в заданном диапазоне одинакова). Приоритеты элементов в дереве случайного поиска определяют их положение в дереве в соответствии с правилом: приоритет каждого элемента в дереве не должен быть более приоритета любого из его последователей. Правило двоичного дерева поиска также остается справедливым: для каждого элемента х элементы в левом поддереве х будут меньше, чем х, а в правом поддереве — больше, чем х. На рис. 1 приведен пример такого дерева случайного поиска.
Рис. 1: Дерево случайного поиска. Приоритеты каждого элемента указаны в виде нижнего индекса
Как же осуществить ввод некоторого элемента х в дерево случайного поиска? Он выполняется в два этапа. На первом этапе будем учитывать приоритет и введем элемент х уже известным нам способом: проследуем по пути поиска элемента я от корня вниз до внешнего узла, которому принадлежит х, и затем заменим внешний узел новым внутренним узлом, содержащим х. На втором этапе мы изменим форму дерева в соответствии с приоритетами элементов. Сначала случайным образом зададим приоритет для х. В простейшем случае, приоритет х может быть больше и равен приоритету предка, тогда задача оказывается решенной. В противном случае, если приоритет х оказывается меньше приоритета его предка у, то правило приоритета для у оказывается нарушенным. Предположим, что элемент х оказался левым наследником для у. В этом случае применим правую ротацию для элемента у, переместив элемент х в дереве на один уровень выше (рис. 2). Теперь правило приоритета может оказаться нарушенным для нового предка элемента х. Если это так, то применим ротацию для предка — правую ротацию, если х является левым потомком, или левую ротацию, если х является правым потомком, переместив таким образом элемент х еще на один уровень вверх. Такой подъем элемента х будем осуществлять до тех пор, пока он не станет либо корневым, либо его приоритет будет не меньше, чем у его предка.
Рис. 2: Ротация
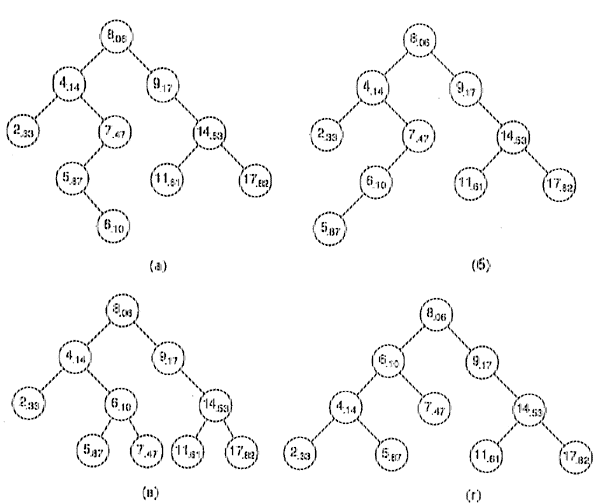
Рис. 3: Внесение элемента 6 в дерево случайного поиска: (а) и (б)—левая ротация элемента 5; (б) и (в) — правая ротация элемента 7; (в) и (г) - левая ротация элемента 4
На рис. 3 показан процесс внесения элемента. На этой схеме показано, как элемент 6 заменяет соответствующий внешний узел, а затем поднимается вверх в соответствии с его приоритетом (.10) и приоритетами его текущих предков.
Определим теперь соответствующие классы. Несколько позже рассмотрим, как удалить элемент из дерева случайного поиска. Реализация использует классы из описания связанного дерева поиска.
Класс RandomizedNode
Узлы в дереве случайного поиска являются объектами шаблона класса RandomizedNode:
template<class T>
class RandomizedNode : public BraidedNode<T> {
protected :
RandomizedNode *_parent;
double _priority;
void rotateRight (void);
void rotateLeft (void);
void bubbleUp (void);
void bubbleDown (void);
public :
RandomizedNode ( Т v, int seed = -1);
RandomizedNode *lchild (void);
RandomizedNode *rchild(void);
RandomizedNode *next (void);
RandomizedNode *prev{ void);
RandomizedNode *parent (void);
double priority (void);
friend class RandomizedSearchTree<T>;
};
Класс RandomizedNode наследует пять элементов данных из его базового класса: val, _lchild, _rchild, _prev и _next. В класс включены два дополнительных элемента данных: _parent, который указывает на узел-предок текущего узла, и _priority, приоритет текущего узла.
Конструктор присваивает новому узлу RandomizedNode случайное значение приоритета, используя стандартную функцию языка C++ rand, которая генерирует случайное число в пределах от 0 до RAND_MAX :
Наибольший интерес представляют компонентные функции класса RandomizedNode, объявленные как private (собственные). Первые две выполняют два вида ротации — правую и левую. Правая ротация является локальной операцией, которая изменяет форму дерева поиска, оставляя неизменным порядок следования элементов — до и после выполнения операции предшественник и последователь для каждого узла остаются без изменения. Правая ротация для узла у приводит к повороту поддерева с корнем в узле у вокруг связи от узла у к его левому потомку х (рис. 2). Операция выполняется путем изменения небольшого числа связей: связь с левым потомком узла у заменяется на связь с поддеревом T2, связь с правым потомком узла х заменяется на связь с узлом у, а связь с узлом у (от его предка) заменяется на связь с узлом х.
Компонентная функция rotateRight выполняет правую ротацию для текущего узла, который играет роль узла у. При этом узел х должен быть левым потомком узла у. Для надежности предполагается, что предок узла у существует, поскольку головной узел должен иметь минимальный приоритет — ни одного другого узла не должно быть на уровне головного узла, поэтому все остальные узлы должны иметь своего предка.
Компонентная функция bubbleUp переносит текущий узел вверх по направлению к корню путем многократных ротаций до тех пор, пока приоритет текущего узла не станет больше или равным, чем у его предка. Функция применяется в тех случаях, когда элемент в дереве случайного поиска располагается ниже, чем это следует в соответствии со значением его приоритета. Отметим, что ротация применяется к предку текущего узла.
Компонентная функция bubbleDown переносит текущий узел вниз по направлению к внешним узлам дерева путем многократных ротаций до тех пор, пока приоритет текущего узла не станет меньше или равным приоритетам обоих его потомков. Для ротации ее направление (вправо или влево) зависит от того, какой из потомков текущего узла имеет меньший приоритет. Если, например, приоритет левого потомка меньше, то правая ротация переносит левый потомок вверх на один уровень, а текущий узел перемещается на один уровень вниз. Каждому внешнему узлу приписывается приоритет 2.0, достаточно большой, чтобы ошибочно не переместить его вверх. Функция bubbleDown применяется в тех случаях, когда элемент в дереве случайного поиска располагается выше, чем это следует в соответствии со значением его приоритета. Эта функция будет использована впоследствии для удаления элемента из дерева поиска.
Общедоступные компонентные функции rchild, Ichild, next, prev и parent определяют связи текущего узла с его правым и левым потомками, с последующим и предшествующим узлами и с предком соответственно:
Деревья случайного поиска представляются в виде объектов класса RandomizedSearchTree. Во многих отношениях шаблон класса напоминает класс BraidedSearchTree: элемент данных root указывает на головной узел, win представляет окно, а элемент cmp указывает на функцию сравнения деревьев.
template<class T> class RandomizedsearchTree {
private :
RandomizedNode<T> *root; // головной узел
RandomizedNode<T> *win; // окно
int (*cmp) (T,T); // функция сравнения
void _remove(RandomizedNode<T>*);
public :
RandomizedsearchTree (int (*) (T,T) , int = -1);
~RandomizedsearchTree (void);
Т next (void);
Т prev(void);
void inorder (void (*) (T) );
Т val (void);
bool isFirst (void);
bool isLast (void);
bool isHead(void);
bool isEmpty (void);
Т find (T);
Т findMin (void);
T locate (T);
T insert (T);
void remove (void);
T remove (T);
T removeMin (void);
};
Конструкторы и деструкторы
Конструктор RandomizedsearchTree инициализирует новое дерево случайного поиска, представляемое изолированным головным узлом с минимальным приоритетом, равным -1,0:
Компонентные функции find и findMin применяются также подобно их аналогам в классе BraidedSearchTree :
template<class Т> Т RandomizedSearchTree<T>::find (T val)
{
RandomizedNode<T> *n = root->rchild ( );
while (n) {
int result = (*cmp) (val, n->val);
if (result < 0)
n = n->lchild();
else if (result > 0)
n = n->rchild();
else {
win = n;
return n->val;
}
}
return NULL;
}
template<class T> Т RandomizedSearchTree<T>::findMin (void)
{
win = root->next();
return win->val;
}
Теперь мы введем новую операцию поиска locate. При обращении к функции locate с аргументом val возвращается наибольший элемент в дереве, который не больше, чем значение val. Если в дереве присутствует элемент со значением val, то возвращается значение val. Если такого значения нет, то возвращается значение меньше, чем val, если же в дереве и такого значения нет, то возвращается NULL.
Для выполнения этой операции будем отслеживать путь по дереву поиска до значения val. По мере продвижения вниз запоминается последний (самый нижний) узел b, в котором поворачиваем вправо — узел b является самым нижним узлом, обнаруженным на пути поиска, для которого правый потомок также лежит на пути поиска. Если в дереве находится значение val, то оно просто возвращается. В противном случае, если мы не найдем значение val в дереве — путь поиска завершается на внешнем узле — то возвращается элемент, запомненный в узле b.
Операция реализуется компонентной функцией locate, в которой окно перемещается на обнаруженный элемент и возвращается этот элемент.
template<class Т> Т RandomizedSearchTree<T>::locate (T val)
{
RandomizedNode<T> *b = root;
RandomizedNode<T> *n = root->rchild();
while (n) {
int result = (*cmp) (val, n->val);
if (result < 0)
n = n->lchild();
else if (result > 0) {
b = n;
n = n->rchild();
} else {
win = n;
return win->val;
}
}
win = b;
return win->val;
}
Каким же образом получается правильный результат? Он вполне очевиден, если значение val точно находится в дереве. Но предположим, что такого значения в дереве нет, поэтому поиск значения val завершается на внешнем узле. Поскольку указатель n сигнализирует об окончании поиска, значение b показывает на наибольший элемент, который меньше всех остальных, содержащихся в поддереве с корнем в узле n. Легко видеть, что это условие сохраняется всегда. Каждый раз, когда в процессе поиска в узле n мы переходим на левую ветвь, условие продолжает сохраняться, поскольку каждый элемент в левом поддереве узла n меньше элемента в узле n. При переходе в узле n на правую ветвь присваивание b значения, равного n, восстанавливает условие, поскольку: (1) каждый элемент в правом поддереве узла n больше элемента, хранящегося в n и (2) элемент, хранящийся в узле n больше, чем элемент, на который указывало значение b до его изменения. И, наконец, когда n указывает на внешний узел, то b будет наибольшим элементом в дереве, который меньше любого другого элемента, который может легально заменить внешний узел, среди которых находится также и val.
Включение элементов
Для внесения нового элемента в дерево случайного поиска сначала найдем внешний узел, к которому он принадлежит (этап 1), а затем будем его поднимать по дереву по направлению к корню в соответствии с его приоритетом (этап 2). Компонентная функция insert заносит элемент val в текущее дерево случайного поиска и затем перемещает окно на этот элемент и возвращает указатель на этот элемент:
template<class T> T RandomizedSearchTree<T>::insert (T val)
{
// этап 1
int result = 1;
RandomizedNode<T> *p = root;
RandomizedNode<T> *n = root->rchild();
while (n) {
p = n;
result = (*cmp) (val, p->val);
if (result < 0)
n = p->lchild();
else if (result > 0)
n = p->rchild();
else
return NULL;
}
win = new RandomizedNode<T>(val);
win->_parent = p;
if (result < 0) {
p->_lchild = win;
p->prev()->Node::insert(win);
} else {
p->_rchild = win;
p->Node::insert(win);
}
// этап 2
win->bubbleUp ();
return val;
}
Удаление элементов
Компонентная функция remove удаляет элемент в окне и затем перемещает окно в предшествующую позицию. Компонентная функция removeMin (удаляет наименьший элемент и возвращает его. Если окно находилось на этом элементе, то оно перемещается в головную позицию:
template<class T> void RandomizedSearchTree<T>::remove(void)
{
if (win != root)
_remove(win);
}
template<class T> Т RandomizedSearchTree<T>::removeMin(void)
{
Т val = root->next()->val;
if (root != root->next() )
_remove(root->next());
return val;
}
Обе эти функции основаны на внутренней компонентной функции _remove. Для удаления узла n функция _remove увеличивает приоритет узла n до 1.5 и затем опускает его вниз до тех пор, пока он не станет внешним узлом. Приоритет 1.5 превышает приоритет любого элемента в дереве, но меньше, чем приоритет внешних узлов (2.0). После этого функция удаляет узел n из дерева случайного поиска. Если окно было на узле, подлежащем удалению, то окно перемещается на предшествующую позицию. Алгоритм реализуется в виде функции _remove, которая удаляет узел n из екущего дерева поиска.
На рис. 3, если его анализировать от (г) до (а), показано удаление элемента 6 из самого правого дерева поиска, для которого приоритет был увеличен до 1.5. Процесс удаления обратен процессу внесения элемента 6 в дерево (а), поскольку правая и левая ротации взаимно обратны.
Для удобства введем вторую компонентную функцию remove, которая, при передаче ей элемента, удаляет его из дерева случайного поиска. Если окно находится на элементе, подлежащем удалению, то окно перемещаетвя в предыдущую позицию, в противном случае окно не перемещается:
template<class Т> Т RandomizedSearchTree<T>::remove (T val)
{
Т v = find (val);
if (v) {
remove();
return v;
}
return NULL;
}
Ожидаемые характеристики
В дереве случайного поиска размера n средняя глубина узла равна O(log n), Это справедливо независимо от изменений в порядке ввода элементов или положения в дереве, куда эти элементы вводятся или из которого удаляются. Поскольку выполнение каждой из операций ввода и удаления insert, remove и removeMin, а также операций поиска find и findMin занимает время, пропорциональное глубине обрабатываемого элемента, то в среднем затраты времени равны 0(log n).
Почему же средняя длина поиска равна O(log n) ? Чтобы ответить на этот вопрос, найдем ожидаемую глубину элемента в дереве случайного поиска Т. Переименуем элементы в дереве поиска Т по увеличивающемуся приоритету как x1, x2,..., xn. Для определения ожидаемой глубины элемента зд предположим, что дерево Т строилось путем занесения элементов в указанном порядке в первоначально пустое дерево случайного поиска Т'. По мере ввода каждого элемента xi определим вероятность того, что оно лежит на пути поиска элемента хk в дереве Т.
Прежде, чем продолжать дальше, обсудим три момента. Во-первых, процесс имеет место в дереве Т, поскольку дерево случайного поиска полностью определяется его элементами и их приоритетами (если даже некоторые значения приоритетов встречаются более одного раза, то элементы все равно могут быть упорядочены таким образом, что дерево Т существует). Во-вторых, вследствие принятого порядка включения элементов не требуется никаких операций ротаций. В-третьих, наш анализ требует, чтобы были внеcены только элементы х1,..., xk1, поскольку элемент хk всегда обязательно
содится в конце своего пути поиска и внесение элементов хk+1,..., xn не может увеличить глубину элемента xk, поскольку ни один из этих элементов не может быть предшественником элемента xk.
Начнем с пустого двоичного дерева Т', представленного единственным аешним узлом. Для внесения элемента х1 в Т' заменим внешний узел на 1. Поскольку элемент x1 находится в корне дерева Т', то он будет предшественником любого элемента xk, так что вероятность того, что элемент x1 лежит на пути поиска элемента xk равна единице. Внесем теперь в дерево элемент x2. Очевидно, что элемент x2 может заменить любой из двух внешних узлов, которые являются последователями элемента х1, так что только одна из этих двух позиций приведет к тому, что элемент x2 будет лежать на пути поиска элемента xk. Поэтому вероятность того, что элемент x2 будет лежать на этом пути поиска, равна 1/2. В общем случае, при вводе в дерево Т' элемента xi, где i изменяется от 1 до k, элемент xi с равной вероятностью замещает один из i внешних узлов. Поскольку только одна из этих позиций приводит к тому, что элемент хi будет лежать на пути поиска цемента хk, то вероятность того, что элемент xi лежит на пути поиска эле-ента xk будет равна 1/i. Из этого следует, что ожидаемая глубина элемента равна 1 + СУММА(1/i), i=1..k-1, что соответствует O(log n) для k <= n.