Donald E. Knuth and Ronald W. Moor
Перевел Павел Н. Дубнер
18 Мая 1998 г. e-mail: infoscope@writeme.com
Здесь вы увидите перевод статьи Д.Е.Кнута и Р.У.Мура, опубликованной в журнале "Artificial Intelligence" аж в 1975 году. Перевод был подготовлен довольно давно - около 1995 года. Здесь и сейчас я лишь исправил замеченные опечатки, добавил "форматирование", возможности, предоставленные нынешним уровнем технологии, а также перевел текст в HTML-формат. Имеется также текст, где содержится пример к этой статье, - в нем описана программа, играющая в КАЛАХ.
0. Введение
При поиске хода в таких играх, как шахматы, программам для ЭВМ приходится
производить просмотр большого дерева возможных продолжений. Чтобы ускорить
этот процесс и не потерять информацию, обычно используют метод, называемый
альфа-бета отсечениями (в советской литературе его называют методом граней
и оценок - прим. переводчика). В данной статье описываются результаты
анализа этой процедуры, проведенного для того, чтобы получить хоть какие-то
численные оценки качества ее работы.
В разд. 1 определены основные понятия, связанные с деревом игры. В разд.
2 описывается процедура, называемая альфа-бета отсечениями (alpha-beta
pruning), и тесно связанный с ней метод, который, однако, не столь эффективен,
поскольку он не производит "нижних отсечений"; здесь же доказана корректность
обоих методов. Примеры работы алгоритмов и более подробное их представление
содержатся в разд. 3. В разд. 4 излагаются некоторые способы практического
применения метода, а разд. 5 посвящен истории альфа-бета отсечений.
В разд. 6 начинается анализ работы метода - получена нижняя оценка трудоемкости
поиска, необходимого процедуре или любому другому алгоритму, который решает
ту же задачу. Верхняя оценка трудоемкости получена в разд. 7 на основе
анализа работы с случайными деревьями, когда не производятся нижние отсечения.
Показано, что даже в этих условиях могут быть получены разумные результаты.
В разд. 8 в анализ включены нижние отсечения, а в разд. 9 показано, что
эффективность возрастает, если между последовательными ходами имеется связь.
Эта работа в значительной степени замкнута, лишь в последних разделах появляется
немножко математики.
1. Игры и оценки позиций
Игры двух лиц, а только с ними мы и имеем здесь дело, обычно описывают
множеством "позиций" и совокупностью правил перехода из одной позиции в
другую, причем предполагают, что игроки ходят по очереди. Будем считать,
что правилами разрешены лишь конечные последовательности позиций и что
в каждой позиции имеется лишь конечное число разрешенных ходов. Тогда для
каждой позиции p найдется число N(p) такое, что никакая игра,
начавшаяся в p, не может продолжаться более N(p) ходов -
это следует из "леммы о бесконечности" (см. [11, п. 2.3.4.3]).
Терминальными называются позиции, из которых нет разрешенных ходов.
На каждой из них определена целочисленная функция f(p), задающая
выигрыш того из игроков, которому принадлежит ход в этой позиции; выигрыш
второго игрока считается равным -f(p).
Если из позиции p имеется d разрешенных ходов p1,...,pd,
возникает проблема выбора лучшего из них. Будем называть ход наилучшим,
если по окончании игры он приносит наибольший возможный выигрыш при условии,
что противник выбирает ходы, наилучшие для него (в том же смысле). Пусть
F(p)
есть наибольший выигрыш, достижимый в позиции p игроком, которому
принадлежит очередь хода, против оптимальной защиты. Т.к. после хода в
позицию pi выигрыш этого игрока равен -F(pi),
имеем
(1)
Эта формула позволяет индуктивно определить
F(p) для каждой позиции p.
В большинстве работы по теории игр используется чуть иная формулировка;
в ней игроки называются Max и Min и изложение ведется с "точки
зрения" игрока Max. Таким образом, если p есть терминальная позиция
с ходом Max, его выигрыш равен, как и раньше f(p), если же
в терминальной позиции p ходить должен Min, то его выигрыш равен
(2) g(p) = -f(p).
Max пытается максимизировать свой конечный выигрыш, а Min
старается минимизировать его. Соотношению (1) при этом соответствуют две
функции, именно
(1') ,
которая задает максимальный гарантированный выигрыш игрока Max
в позиции p, и
(1'') ,
которая равна оптимуму, достижимому для игрока Min. Как и раньше,
здесь предполагается, что p1,...,pd есть разрешенные
в позиции p ходы. Индукцией по числу ходов легко показать, что функции,
определяемые соотношениями (1) и (3), совпадают и что для всех p
(5) G(p) = -F(p).
Таким образом, оба подхода эквивалентны.
Т.к. нам обычно легче оценивать позиции с точки зрения одного какого-то
игрока, иногда удобнее использовать "минимаксный" подход (3) и (4), а не
рассуждать в "плюс-минус-максимальных" терминах соотношения (1). С другой
стороны, соотношение (1) предпочтительнее, когда мы хотим доказать что-нибудь,
- при этом нам не приходится исследовать два (или больше - по числу игроков)
разных случая.
Функция F(p) равна тому максимуму, который гарантирован, если
оба игрока действуют оптимально. Следует, однако, заметить, что она отражает
результаты весьма осторожной стратегии, которая не обязательно хороша против
плохих игроков или игроков, действующих согласно другому принципу оптимальности.
Пусть, например, имеются два хода в позиции p1 и p2,
причем p1 гарантирует ничью (выигрыш 0) и не дает возможности
выиграть, в то время, как p2 дает возможность выиграть,
если противник просмотрит очень тонкий выигрывающий ход. В такой ситуации
мы можем предпочесть рискованный ход в p2, если только
мы не уверены в том, что наш противник всемогущ и всезнающ. Очень возможно,
что люди выигрывают у шахматных программ таким именно образом.
2. Разработка алгоритма
Нижеследующий алгоритм (на специально придуманном алголоподобном языке),
очевидно, вычисляет F(p) в соответствии с определением (1):
integer procedure F(position p):
begin integer m,i,t,d;
Определить позиции p1,...,pd, подчиненные p;
if d = 0 then F := f(p) else
begin
m := -(infinity);
for i:= 1 step 1 until d do
begin
t := -F(pi);
if t > m then m:= t;
end;
F := m;
end;
end.
Здесь + обозначает
число, которое не меньше abs(f(p)) для любой терминальной позиции
p;
поэтому -
не больше F(p) и -F(p) для всех p. Этот алгоритм вычисляет F(p)
на основе "грубой силы": для каждой позиции он оценивает все возможные
продолжения; "лемма о бесконечности" гарантирует окончание вычислений за
конечное число ходов.
Перебор, который осуществляет этот алгоритм, можно уменьшить, используя
идею метода "ветвей и границ" [14]. Идея состоит в том, что можно не искать
точную оценку хода, про который стало известно, что он не может быть лучше,
чем один из ходов, рассмотренных раньше. Пусть, например, в процессе перебора
стало известно, что F(p1) = -10. Мы заключаем отсюда,
что F(p)10,
и потому нам не нужно знать точное значение
F(p2), если
каким-либо образом мы как-то узнали, что
F(p2)-1
(и, таким образом, что -F(p2)10).
Итак, если p21 допустимый ход из p2
и F(p21)10,
мы можем не исследовать другие ходы из
p2. В терминах
теории игр ход в позицию p2 "опровергается" (относительно
хода в p1), если у противника в позиции p2
есть ответ, по крайней мере столь же хороший, как его лучший ответ в позиции
p1.
Ясно, что если ход можно опровергнуть, мы можем не искать наилучшее опровержение.
Эти рассуждения приводят к алгоритму, гораздо более экономному, чем
F.
Определим F1 как процедуру с двумя параметрами p и bound;
наша цель - удовлетворить следующим условиям:
F1(p, bound) = F(p), если F(p) < bound,
(6)
F1(p, bound) > bound, если F(p) > bound.
Эти условия не определяют F1 полностью, однако, позволяют вычислить
F(p)
для любой начальной позиции p, поскольку из них следует, что
(7) F1(p,+
) = F(p).
Идею метода ветвей и границ реализует следующий алгоритм:
integer procedure F1(position p, integer bound):
begin integer m,i,t,d;
Определить позиции p1,...,pd, подчиненные p;
if d = 0 then F1 := f(p) else
begin m := -(infinity);
for i:= 1 step 1 until d do
begin
t := -F1(pi, -m);
if t > m then m := t;
if m >= bound then goto done;
end;
done: F1 := m;
end;
end.
Правильность работы этой процедуры и то, что результат удовлетворяет соот-ношениям
(6), можно доказать следующими рассуждениями. Легко видеть, что в начале
i-го витка for-оператора выполнено "инвариантное" условие
(8) m = max { -F(p1), ..., -F(pi-1)}.
Здесь предполагается, что максимум по пустому множеству даст -.
Поэтому, если -F(pi) > m, то, используя условие (6) и
индукцию по длине игры, начинающейся в p, получаем F1(pi,-m)
= F(pi). Следовательно, в начале следующего витка (8) также
будет выполнено. Если же max {-F(p1,...,-F(pi)}
bound при всех i, то F(p)
bound. Отсюда следует, что (6) выполняется для всех p.
Эту процедуру можно еще улучшить, если ввести не только верхнюю, но
и нижнюю границу. Эта идея - ее называют минимаксной альфа-бета процедурой
или просто альфа-бета отсечениями - является значительным продвижением
по сравнению с односторонним методом ветвей и границ. (К сожалению, она
применима не во всех задачах, где используется метод ветвей и границ; она
работает только при исследовании игровых деревьев.) Определим процедуру
F2
с тремя параметрами p, alpha и beta (причем всегда будет
выполнено alpha < beta), которая удовлетворяет следующим условиям,
аналогичным (6):
F2(p,alpha,beta)
alpha, если F(p) < alpha,
(9) F2(p,alpha,beta) = F(p), если alpha < F(p) < beta,
F2(p,alpha,beta)
beta, если F(p)
beta.
И снова эти условия не определяют F2 полностью, однако, из них
следует, что
(10) F2(p,-,
+) = F(p).
Оказывается, представление этого улучшенного алгоритма на языке программирования
лишь чуть-чуть отличается от алгоритмов F и F1:
integer procedure F2(position p, integer alpha, integer beta):
begin integer m,i,t,d;
Определить позиции p1,...,pd, подчиненные p;
if d = 0 then F2 := f(p) else
begin m := alpha;
for i:= 1 step 1 until d do
begin t := -F2(pi, -beta, -m);
if t > m then m := t;
if m >= beta then goto done;
end;
done: F2 := m;
end;
end.
3. Примеры и уточнения
Работу этих процедур проиллюстрируем на примере дерева (рис. 1), с корнем
в позиции с тремя подчиненными позициями, у каждой из которых также имеются
три подчиненных позиции, и т.д. до тех пор, пока мы не получим 3**4 = 81
позиций, достижимых за 4 хода. Этим терминальным позициям приписаны "случайные"
оценки, которые равны первым 81 цифрам десятичного разложения числа pi.
Таким образом, корень дерева (расположенный вверху) имеет оценку 2, равную
выигрышу первого игрока, если оба игрока делают оптимальные ходы.
Рис.1. Полностью оцененное дерево игры.
На рис. 2 представлена ситуация, соответствующая перебору, который производит
процедура F1. Заметим, что из 81 терминальных позиций она "посещает"
только 36. Кроме того, одна из вершин 2-го уровня имеет "приближенную"
оценку 3 вместо истинного значения 7; эта приблизительность, конечно, не
влияет на конечную оценку корня.
Рис.2. Дерево игры, представленное на рис. 1, после оценки процедурой
F1 (метод ветвей и границ).
На рис. 3 представлена та же задача, решаемая альфа-бета процедурой.
Обратите внимание на то, что F2(p,-,
+) всегда
исследует те же узлы, что и F1(p,+
), пока не достигнет вершин четвертого уровня; это есть следствие развиваемой
ниже теории. На уровнях 4, 5, ..., однако, процедура F2 способна
производить "нижние отсечения", на которые неспособна F1. Сравнение
рис. 3 и рис. 2 показывает, что в этом примере сделано 5 нижних отсечений.
Рис3. Дерево игры, представленное на рис. 1, после оценки процедурой
F2 (альфа-бета стратегия).
Все иллюстрации представлены в терминах "отрицательно-максимальной"
модели, рассмотренной в разд. 1; тем, кто предпочитает "минимаксную" терминологию,
достаточно игнорировать на рис. 1-3 минусы. Процедуры разд. 2 легко представить
в минимаксном виде, заменив, например,
F2 следующими двумя процедурами:
integer procedure F2(position p, integer alpha, integer beta):
begin integer m,i,t,d;
Определить позиции p1,...,pd, подчиненные p;
if d = 0 then F2 := f(p) else
begin m := alpha;
for i:= 1 step 1 until d do
begin t := G2(pi, m, beta);
if t > m then m := t;
if m >= beta then goto done;
end;
done: F2 := m;
end;
end;
integer procedure G2(position p, integer alpha, integer beta):
begin integer m,i,t,d;
Определить позиции p1,...,pd, подчиненные p;
if d = 0 then G2 := g(p) else
begin m := alpha;
for i:= 1 step 1 until d do
begin t := F2(pi, alpha, m);
if( t > m then m := t;
if m >= beta then goto done;
end;
done: F2 := m;
end;
end.
В качестве легкого, но поучительного упражнения предлагается доказать,
что G2(p,alpha,beta) всегда равняется -F2(p,-beta,-alhpa).
В приведенных процедурах используется волшебная подпрограмма, которая
определяет позиции p1,...,pd, подчиненные
позиции p. Если мы захотим более точно описать способ представления
позиций, нам естественно использовать списковую структуру. Пусть p
есть ссылка на запись, соответствующую исходной позиции, тогда first(p)
есть ссылка на первую подчиненную позицию или NULL (пустая ссылка),
если позиция p терминальная. Аналогично, если q есть ссылка
на запись, соответствующую pi, то next(q) есть
ссылка на следующую подчиненную позицию pi+1 или
NULL,
если i = d. Наконец, через generate(p) обозначим процедуру,
которая создает записи, соответствующие позициям p1,...,pd,
устанавливает в этих записях поля next и делает так, что first(p) указывает
на p1 или равняется NULL, если d = 0. Тогда
альфа-бета процедуру можно представить в следующей более точной форме:
integer procedure F2(ref(position) p,integer alpha,integer beta):
begin integer m,t; ref(position) q;
generate(p);
q := first(p);
if q = NULL then F2 := f(p) else
begin m := alpha;
while q<=NULL and m < beta do
begin t := -F2(q, -beta, -m);
if t > m then m := t;
q := next(q);
end;
F2 := m;
end;
end.
Интересно представить эту рекуррентную процедуру в итеративном (нерекуррентном)
виде и испробовать простые оптимизирующие преобразования, которые сохраняют
корректность программы (см. [13]). Результирующая процедура удивительно
проста, хотя доказательство ее правильности не столь очевидно, как для
рекуррентного представления:
integer procedure alphabeta(ref(position p);
begin integer l; comment level of recursion;
integer array a[-2:L];
comment stack for recursion where a[l-2], a[l-1], a[l]
denote respectively alpha, beta, m, -t in procedure F2;
ref (position) array r[0:L+1];
comment another stack for recursion where r[l] and r[l+1]
denote respectively p and q in F2;
l := 0; a[-2] := a[-1] := -(infinity); r[0] := p;
F2: generate(r[l]);
r[l+1] := first(r[l]);
if r[l+1] = NIL then a[l] := f(r[l]) else
begin a[l] := a[l-2];
loop: l := l+1; goto F2;
resume: if -a[l+1] > a[l] then
begin a[l] := -a[l+1];
if a[l+1] <= a[l-1] then go to done;
end;
r[l+1] := next(r[l+1]);
if r[l+1]<=NIL then goto loop;
end;
done: l := l-1; if l >= 0 then goto resume;
alphabeta := a[0];
end.
Эта процедура вычисляет то же значение, что и F2(p,-,+);
значение
L
нужно выбрать настолько большим, чтобы уровень рекурсии никогда не превосходил
L.
4. Приложения
Разрабатывая игровую программу, мы редко можем надеяться, что при оценке
очередного хода она сможет добираться до терминальных узлов - даже альфа-бета
отсечения недостаточно быстры, чтобы играть в "оптимальные" шахматы! Тем
не менее, описанные процедуры применять можно, если подпрограмму, генерирующую
очередные позиции (ходы) изменить так, чтобы достаточно глубокие позиции
она объявляла терминальными. Пусть, например, мы хотим вести перебор на
глубину в 6 полуходов (по 3 на каждого игрока). В этом случае мы можем
притвориться, что в позициях, находящихся на 6-м уровне от оцениваемой,
нет допустимых ходов (т.е. они терминальные). Для вычисления оценок таких
"искусственно терминальных" позиций нам нужно, конечно, использовать все
возможные данные, всю нашу догадливость, надеясь при этом, что достаточно
глубокий поиск смягчит последствия допущенных ошибок. (Большая часть времени
работы программы будет затрачена на вычисление таких догадок, поэтому приходится
использовать быстро вычислимые оценки. Другая возможность состоит в разработке
генератора допустимых ходов, однако, эта задача чрезвычайно трудна.)
Вместо поиска на фиксированную глубину можно исследовать некоторые ветви
(последовательности дуг-ходов) дерева подробнее, скажем, исследовать до
конца размены. Интересный подход предложил в 1965 г. Р.Флойд [6], хотя
пока что его не исследовали достаточно широко. Каждому ходу в схеме Флойда
присваивается некое "правдоподобие" согласно следующему общему плану. "Правдоподобие"
вынужденного хода равняется 1, в то время как маловероятным ходам (таким,
как жертва ферзя в шахматах) присваивается "правдоподобие", равное, скажем,
0.01 или около того. В шахматах ответное взятие имеет правдоподобие, большее
0.5, а наихудшие ходы - около, скажем, 0.02. Когда произведение правдоподобий
ходов, ведущих в некую позицию, становится меньше выбранного порога - например,
меньше 10-8), эта позиция рассматривается как терминальная,
поиск дальше не ведется и вычисляется ее оценка. В этой схеме "наиболее
вероятным" ветвям дерева уделяется наибольшее внимание.
Какой бы метод ни использовался для получения дерева приемлемых размеров,
сама альфа-бета процедура допускает улучшение, если мы представляем себе,
чему может быть равна оценка исходной позиции. Если мы думаем, что оценка
позиции больше a и меньше b, то вместо
F2(p, -,
+) мы можем
испробовать F2(p,a,b). Скажем, в примере на рис. 3 можно вместо
F2(p,-10,+10)
использовать F2(p,0,4) - при этом "-4" на уровне 3 и подчиненные
позиции будут отсечены. Если наше предположение верно, мы отсечем большую
часть дерева; с другой стороны, если полученная оценка окажется слишком
низкой, скажем F2(p,a,b) = v, где va, мы можем повторить поиск с
F2(p,-,v),
чтобы получить верную оценку. Эта идея использована в некоторых версиях
шахматной программы Гринблатта [8].
5. История
Прежде чем мы приступим к количественному анализу эффективности альфа-бета
процедуры, кратко рассмотрим основные этапы ее развития. Ее ранняя история
достаточно туманна, потому что она основывается на недокументированных
воспоминаниях, а также потому, что иногда путают процедуру F1 с
более мощной процедурой F2, поэтому нижеследующее изложение использует
наиболее точную информацию, доступную авторам.
Мак-Карти думал о подобном методе в 1965 г. во время Дартмутской летней
исследовательской конференции по искусственному интеллекту, где Бернстайн
рассказал об одной из самых ранних шахматных программ [3], в которой не
использовались никакие отсечения. Мак-Карти "критиковал за это программу,
но не убедил Бернстайна. В то время спецификации алгоритма подготовлены
не были". Очень вероятно, что замечания Мак-Карти, сделанные на этой конференции,
привели к тому, что в конце 50-х гг. альфа-бета отсечения стали использовать
в шахматных программах.
Первой публикацией, в которой содержалось обсуждение отсечений в дереве
игры, была статья Ньюэлла, Саймона и Шоу [16] с описанием их ранней шахматной
программы. Однако, они привели примеры работы лишь "одностороннего" метода,
реализованного в процедуре F1, так что неясно, были ли использованы "нижние"
отсечения.
Мак-Карти ввел идентификаторы alpha и beta в своей первой
программе на LISP'е, реализующей этот метод. Его программа работала даже
более изощренно, чем вышеописанный метод, поскольку он предполагал существование
двух функций "оптимистическая оценка (p)" и "пессимистическая
оценка (p)", которые доставляли верхнюю и нижнюю границы оценки позиции.
Программу Мак-Карти, выполняющую те же действия, что приведенная выше процедура
F2,
можно представить в следующем виде:
if optimistic value(p)
alpha then F2 := alpha
else if pessimistic value(p)
beta then F2 := beta
else begin <the above body of procedure F2> end.
Из-за этих добавлений Мак-Карти считал альфа-бета отсечения (возможно,
дающим ошибку) эвристическим приемом, не осознав, что точное значение оценки
получается, когда для всех p
optimistic value(p) = +
и
pessimistic value(p) = -
Он подарил открытие этого факта Харту и Эдвардсу, которые в 1961 году
подготовили по этому поводу отчет [10]. В этом неопубликованном отчете
они приводят примеры работы общего метода, в том числе, нижних отсечений.
Однако (как это было принято в 1961 г.), в нем нет ни обоснования метода,
ни указания условий, при которых он работает.
Первая публикация с описанием альфа-бета отсечений появилась на русском
языке в 1963 г. совершенно независимо от работ американцев. Брудно [4]
один из разработчиков первых версий русской шахматной программы (имеется
в виду программа, которую позже назвали романтическим именем КАИССА в честь
музы шахмат - прим. перев.), предложил алгоритм, совпадающий с альфа-бета
методом, и дал - довольно-таки сложное - доказательство его правильности.
Полное описание альфа-бета отсечений появилось в "западной" литературе
по вычислениям и компьютерам в 1968 г. в статье Слейгла и Бурского [24]
о стратегиях доказательства теорем, однако, это описание страдало нечеткостью
и не содержало обсуждения нижних отсечений. Таким образом, можно утверждать,
что первое четкое изложение метода на английском языке появилось в 1969
г. в статьях Слейгла и Диксона [25] и Самуэля [22]; в обеих статьях явно
упоминается возможность нижних отсечений и обсуждение идеи включает необходимые
детали.
Практика показывает, что очень трудно объяснить метод построения альфа-бета
отсечений "на словах" или на обычном математическом языке, поэтому авторы
цитированных выше работ были вынуждены прибегать к длинным и сложным описаниям.
Более того, при первом знакомстве с методом очень трудно заставить себя
поверить в то, что он действительно работает, особенно тогда, когда методы
описывают на "обычном" языке и пытаются обосновать возможность нижних отсечений.
Быть может, именно поэтому описание метода появилось спустя много лет после
того, как он был изобретен. Однако, в разд. 2 мы видели, что метод легко
понять и обосновать, если выразить его на алгоритмическом языке; это является
хорошим примером случая, в котором "динамический" подход к описанию процесса
оказывается значительно более предпочтительным, чем обычный математический.
Очень хорошо метод описан в недавних книгах Нильсона [18, разд.4] и
Слейгла [23, pp.16-24], однако, они представляют метод "в прозе", а не
в более легкой для понимания алгоритмической форме. Альфа-бета отсечения
стали "широко известными", однако, насколько известно авторам, лишь в двух
публикациях процедура описана на алгоритмическом языке. На самом деле,
в первой из них [27, раз. 4.3.3], Уэллс приводит не полную альфа-бета процедуру,
а нечто даже более слабое, чем процедура F1. (Его алгоритм не только
не производит нижние отсечения, но и верхние отсечения производит лишь
при выполнении строгого неравенства.) Другая версия алгоритма, принадлежащая
Далу и Белснису [5, разд. 8.1], появилась в недавно вышедшем на норвежском
языке учебнике по структурам данных; однако, альфа-бета метод представлен
в ней с использованием параметров-меток, так что доказательство правильности
становится достаточно трудным. В другом недавнем учебнике [17, разд. 3.3.1]
содержится неформальное описание того, что там названо "альфа-бета отсечениями",
но снова приведен лишь метод, реализуемый процедурой
F1; по-видимому,
многие не знают, что альфа-бета процедура способна производить нижние отсечения.
(Когда один из авторов статьи (Д.Е.Кнут) около 5 лет назад проделал некоторые
исследования, описанные в разд. 7, он знал, что нижние отсечения возможны.
Однако, процедуру F1 легко принять за "альфа-бета отсечения", о
которых говорят ваши коллеги, так и не открыв F2. -Прим. авторов.)
Из-за всего этого авторы данной статьи уверены в том, что новое изложение
метода окажется полезным, - и это несмотря на то, что альфа-бета отсечения
используют уже более 15 лет!
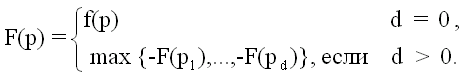
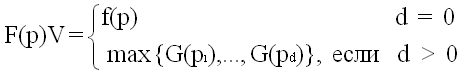 ,
,
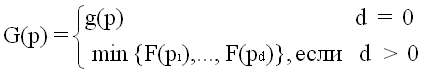 ,
,
 обозначает
число, которое не меньше abs(f(p)) для любой терминальной позиции
p;
поэтому -
обозначает
число, которое не меньше abs(f(p)) для любой терминальной позиции
p;
поэтому -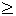 10,
и потому нам не нужно знать точное значение
F(p2), если
каким-либо образом мы как-то узнали, что
F(p2)
10,
и потому нам не нужно знать точное значение
F(p2), если
каким-либо образом мы как-то узнали, что
F(p2)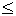 10).
Итак, если p21 допустимый ход из p2
и F(p21)
10).
Итак, если p21 допустимый ход из p2
и F(p21)