Говоря в §1, что описанные там разложения позволяют, в принципе, вычислять
F(x)с
произвольной точностью, я умолчал о том, что точность вычислений ограничивается
не только ошибкой, распространяемой при выполнении арифметических операций
во время суммирования рядов и цепных дробей, но и точностью (числом верных
знаков), с которой задается константа 1/Ц2p,
а также ошибкой, возникающей при вычислении экспоненты. В частности, константу,
возможно, придется заменить при переходе с одной платформы на другую.
Однако, раз уж «чистоту» алгоритмов соблюсти не удалось, наше падение
усугубится не слишком сильно, если мы позволим себе использовать еще несколько
констант. При этом мы основываемся на следующем простом рассуждении.
Скорость сходимости ряда Тейлора, являющаяся одним из главнейших показателей
качества подобных алгоритмов, тем ниже, чем более удалена точка, в которой
мы вычисляем функцию, от точки, в которой эта функция была разложена в
ряд. Поэтому следует запасти несколько разложений в разных точках с тем,
чтобы для каждой точки иметь возможность выбрать из них наилучшее.
Для реализации этого соображения нужно уметь раскладывать в произвольной
точке в ряд Тейлора саму F(x)
или просто связанную с ней функцию. Этим мы сейчас и займемся.
Легко проверить, что F(x)удовлетворяет
соотношению
(1) F"(x)
= -xF'(x).
Разложим F(x)в
ряд Тейлора в точке
y:
(2) .
Положим gn
= hnn!
; из (1)-(2) следует, что удовлетворяют следующему соотношению
(3) gn+2
= -ygn+1 -
ygn, n і
0; g0
= F(x),
g0
= j
(y).
Обратите внимание: при y
= 0 соотношения (2)-(3)
задают ряд (1.1).
Еще разложение для вычисления F(x)можно
получить, исходя из уравнения
(4)
.Из (4) легко получить рекурсивные
соотношения для коэффициентов cn(y)
разложения Тейлора в точке y:
(5)(n+2)cn+2
= ycn+ 1 + cn,
n
і
0; c0
= , c1
= 1 + c0y.
Обратите внимание: при y
= 0 соотношения задают ряд
(1.3).
Легко углядеть, что с ростом y
скорость сходимости обоих разложений довольно быстро падает.
Основываясь на этих разложениях, можно
построить алгоритмы, которые используют возможности степенных рядов более
изощренно, чем бесхитростные алгоритмы I
и T.
Прежде всего, можно попросту запасти
значения вычисляемой функции – F(x)или –
в нескольких точках x1,…,xk
и, выбрав для заданной точки x
ближайшую из запасенных, использовать далее соответствующее разложение.
На этой идее основаны алгоритмы D
и P.
При реализации этих алгоритмов приходится делать выбор между расходом памяти
на хранение значений функции и числом суммируемых членов ряда: чем больше
расстояние между соседними точками, тем меньше расход памяти, но и тем
медленнее, вообще говоря, сходится ряд Тейлора. Можно также решать задачу
поиска оптимального расположения запасаемых точках, но мы здесь не будем
этим заниматься.
Алгоритм D.
Этот алгоритм вычисляет значения функции F(x)
в
точках отрезка |x|Ј
a. Предполагается, что отрезок
[0, a]
разбит на определенное число непересекающихся отрезков с центрами в xi
и известны значения Fi
= F(xi).
Чтобы вычислить F(x),
алгоритм выбирает xi,
для которого расстояние |x-
xi|
минимально; после этого используется разложение (2)-(3) с y=xi.
D1.
Положить x1 = |x|; i = [x1/h]; z =
i*h; /* i – номер ближайшей к x точки xi,
z = xi */ D2.
/* Подготовка к вычислению ряда. */ Положить
g0 = t = Fi;
g1 = exp(-z*z/2)/Ц2p
; xn
= x1 = x1-z; sum=t+g1*xn; n = 1; D3.
/* Вычисление очередной частичной суммы */ Положить
n = n+1; s=-z*g1-(n-2)*g0; g0=g1; g1 = s;
xn=x1*xn/n;s=t; t=sum;
sum = sum + g1*xn; D4.
/* Проверка точности */ Если
|s-t| > e или
|t-sum| > e,
перейти кD3. D5.
Если x > 0 , положить F
= sum, иначе положить F
= 1-sum. На
этом работа алгоритма заканчивается.Алгоритм P.
Вычисления здесь полностью аналогичны тому, что делается в алгоритме D.
Используется разложение (4)-(5) и, соответственно, запасаются значения .
P1.
Положить x1 = |x|.
Положить i = [x1/h]; z = i*h
(теперь i – номер ближайшей к x точки xi,
z = xi).
P2.
/* Подготовка к вычислению ряда. */ Положить
c0 = s = Ri; c1 = 1+z*c0; xn
= x1 = x1-z; rz=s+c1*xn; n = 1. P3.
/* Вычисление очередной частичной суммы */ Положить n = n+1; xn = x1*xn;
s = (c0+z*c1)/n; c0 = c1; c1 = s; s = t; t =
rz; rz = t+c1*xn. P4.
/* Проверка точности */ Если |s-t|
> e или |t-rz|
> e, перейти
к P3.
P5.
Положить 0.5 + sign(x)*rz*exp(-x*x/2)/Ц2p
; на
этом работа алгоритма заканчивается.
Можно действовать и более изысканно, подбираясь
к нужной точке шажками определенной длины и вычисляя значения функции в
промежуточных точках. На этом основаны алгоритмы F
и C,
в которых используется лишь тот факт, что F(0)=0.5,
а =0.
Алгоритм F.
Последовательно вычисляются F(h),
F(2h)и
т.д. до тех пор, пока
kґh
Ј
x и только после этого вычисляется
F(x).
Действия алгоритма напоминают движения
гусеницы, которая переползает из нуля в h,
из h
в 2h
и т.д. до тех пор, пока не доползет до точки x.
F1.
Положить x1 = |x|; z = fz = 0. F2.
/* Проверка окончания */ Положить
a=x1-z. Если a Ј
0, положить F
= 0.5 + sign(x)*fz. На этом работа
алгоритма заканчивается. F3.
/* Установ шага */ Если a > h, положить a = h. F4.
/* Подготовка к вычислению ряда. */ Положить
xn = a; g0 = g1 = exp(-z*z/2)/Ц2p;
t = sum = g1*xn; n = 1. F5.
/* Вычисление очередной частичной суммы ряда */ Положить
n=n+1; xn = xn*a/n; s = -z*g1-(n-2)*g0;
g0 = g1; g1 = s; s = t; t = sum; sum = sum+g1*xn. F6.
/* Проверка точности */ Если |s-t| >>
e или
|t-sum| > e
, перейти к F5.
F7.
/* В т. z разложение посчитано. Пошли в след. точку */ Положить
fz = fz + sum; z = z + a; перейти к F2.Алгоритм C.
Этот алгоритм, основанный на разложении (4)-(5), полностью аналогичен предыдущему.
Значение булевской переменной gotta
становится равным true,
когда нужная точка x
достигнута.
C1.
Положить x1 = |x|; z = Rz = 0; gotta = false. C2.
Положить xa = z; Ra = Rz; z = z + h. Если
z і x1, положить
z = x1; gotta = true. C3.
/* Подготовка к вычислению ряда. */ Положить
c0 = t = Ra; c1 = 1 + xa*Ra;
xn = D = z- xa; Rz = Ra + c1*xn; n = 1. C4.
/* Вычисление очередной частичной суммы ряда */ Положить
n=n+1; xn = D*xn; s = (c0 + xa*c1)/n;
C0 = c1; c1 = s; s = t; t = Rz; Rz = t + c1*xn. C5.
/* Проверка точности */ Если |s-t|
> e или |t-Rz|
> e, перейти
к C4.
C6.
/* Проверка окончания */ Если gotta
= false, перейти к C2. C7.
Положить F =
0.5 + sign(x)*exp(-z*z/2)/Ц2p; на
этом работа алгоритма заканчивается.
Можно также двигаться из x
в
нуль. При этом, однако, удается использовать только разложение (2)-(3).
Соответствующий алгоритм
B
очень близок к алгоритму 123 [8], в котором для вычисления функции ошибок
использовано разложение
(6) ,
где wn
= vn/n!,
а vn
удовлетворяют соотношениям
(7) vn+2
= 2yvn+1-2nvn,
n і
0; v0
= erf(x), v1
= .
Вычисление erf(x) при x
> 0 производится по формуле
erf(x) = -sa(x0)
- sa(x1)
- … - sa(xk),
в которой ,
x0
= x, xi=xi-1-a,
iі
1, причем
,
а k
– наименьшее целое, такое, что xk-1>D.
Алгоритм B.
В этом алгоритме гусеница ползет из x
в нуль с шагом а
(предполагаем, следовательно, что а > 0).
B1.
Положить x1 = |x|; Fz = 0. B2.
/* Проверка окончания */ Если x1
Ј
0, положить F
= 0.5 + sign(x)*Fz. На этом работа
алгоритма заканчивается. B3.
/* Установ шага */ Если x1 Ј
a, положить a = -x1. B4.
/* Подготовка к вычислению Fz */
Положить
g0 = g1 = exp(-x1*x1/2)/Ц2p;
xn = -a; n = 1; t = sum = g1*xn. B5.
/* Вычисление очередной частичной суммы */
Положить
n = n + 1; xn = -a*xn/n;
s = -x1*g1-(n-2)*g0; g0 = g1; g1 = s;
s = t; t = sum; sum = t+g1*xn. B6.
/* Проверка точности */
Если |s-t|
> e или |t-sum|
> e, перейти
кB5.
B7.
/* Передвижение */
Положить
Fz = Fz + sum; x1 = x1 - a; перейти
к B2.
В алгоритме 123 выбрано D=0.5.
В качестве условия останова фигурирует требование, чтобы очередной прибавляемый
член не превосходил по абсолютной величине 10-10.
Основным недостатком алгоритма является возможность преждевременного выхода
из цикла, вычисляющего sa(x).
В самом деле, коэффициенты ряда (6) пропорциональны полиномам Эрмита
.
Поэтому в точках y,
являющихся корнями какого-либо полинома, стандартное условие останова,
которое здесь имеет вид |wn(y)(x-y)n|
Јe
, приводит к неверному результату;
этот факт отмечен в замечании к алгоритму [7]. Условием останова, предохраняющим
от преждевременного обрыва ряда Тейлора, может быть: |sn-sn-1|Јe
& |sn+1-sn|Јe
.
Эти соображения учтены
в алгоритме B.
Алгоритм E.
В этом представлении алгоритма 123 [8] условие останова модифицировано
указанным выше способом. Кроме того, я заменил несколько операторов алгоритма
123 так, что sa(z)
вычисляется чуть более экономно. Наконец, при вычислении F(x),
используется формула F(x)=
(1+erf(x/Ц2))/2.
Для облегчения сравнений использованы те же идентификаторы, что и в исходном
алгоритме.
E1. Положить
x1 = |x|/Ц2;
z = 0. E2.
/* Проверка окончания */
Если x1
Ј
0, положить F
= 0.5 + sign(x)*z; на этом работа
алгоритма заканчивается. E3.
/* Установ шага */ Если x1 Ј
a положить a = x1. E4.
/* Подготовка к вычислению sa(x1)
*/ Положить
n = 1; u = v = exp(-x1*x1)/Цp;
xn = a; s = 0; y = v*a. E5.
/* Вычисление очередной частичной суммы sa(x1)
*/ Положить
n = n+1; w = -2*(x1*v + u(*n-2)); u = v; v
= w; xn = -a*xn/n; w = s; s = y; y = y + v*xn. E6.
/* Проверка точности */
Если |w -
s| > e или |s
- y| > e, перейти
к E5.
E7.
Положить z = z + y; x1 = x1 - a и перейти к E2.
Для проведения численных экспериментов
алгоритмы D,
P,
C,
B
и E
были реализованы на Си. В нижеследующей таблице для каждого алгоритма приводится
количество "витков" цикла, потребовавшихся для вычисления значения с e
= 0 для нескольких x;
поскольку все алгоритмы дали одинаковые 8 знаков после запятой, сами вычисленные
значения опущены.
x
D
P
C
B
E
0.25
14
16
16
16
16
0.50
20
23
20
21
21
0.75
15
18
37
36
34
1.00
1
2
42
42
40
1.25
15
17
59
57
45
1.50
19
25
65
62
60
1.75
15
19
83
78
64
2.00
1
2
88
83
70
2.25
15
18
106
99
85
2.50
19
27
112
104
89
2.75
15
20
131
120
94
3.00
1
2
137
125
111
3.25
15
20
157
141
115
3.50
18
29
163
147
121
3.75
14
21
183
163
135
4.00
1
2
190
168
140
4.25
14
21
211
185
155
4.50
17
32
218
190
161
4.75
13
23
239
206
168
5.00
1
2
246
212
182
5.25
13
22
268
229
190
5.50
15
33
275
235
195
5.75
12
24
297
253
212
6.00
1
2
305
258
218
6.25
12
23
328
277
224
6.50
15
36
336
282
241
6.75
10
25
359
302
247
7.00
1
2
367
307
251
7.25
10
24
391
327
270
7.50
11
38
399
332
275
7.75
6
26
423
353
283
Сравнение результатов работы всех этих
алгоритмов позволяет констатировать здесь полное торжество грубой силы
над красотой и изяществом; здесь даже не нужно учитывать количество операций
внутри цикла – все ясно и без этого. Из алгоритмов P
и D
лучшим оказался алгоритм D.
Если для него понадобятся константы Fi,
я рекомендую вычислять их с помощью смеси алгоритмов T
и L
из §1 с использованием длинной арифметики.
Примечание.
Приводимые
коды алгоритмов из разделов 1 и 3 предназначены лишь для численных экспериментов,
их следует рассматривать лишь как иллюстрации. "Рабочие" коды должны учитывать
множество тонких моментов, среди которых особенно подчеркну продуманную
систему обработки исключительных состояний. (Подобная
система разрабатывается, как правило, сразу для библиотеки функций.) Приведу
лишь один из сонма возможных примеров мелких хитростей, оказывающих решающее
влияние на эффективность программы: в кодах, реализующих алгоритмы
P
и D,
при вычислении i
на самом первом шаге не достаточно отбросить дробную часть – необходимо
честно вычислить целую часть дроби (это отражено в приведенных кодах).
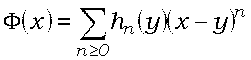 .
.
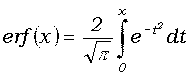
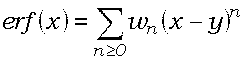 ,
,
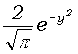 .
.
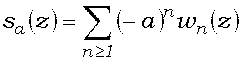 ,
x0
= x, xi=xi-1-a,
iі
1, причем
,
x0
= x, xi=xi-1-a,
iі
1, причем
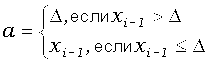 ,
,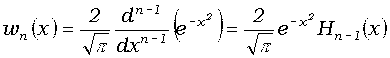 .
.