Подобно тому, как быстрая сортировка изоморфна бинарным деревьям поиска, поразрядная сортировка изоморфна цифровым деревьям поиска (см. Кнут
[11]). Этот изоморфизм описан в таблице:|
Алгоритм |
Структура данных |
|
Быстрая сортировка |
Бинарные деревья поиска |
|
Быстрая сортировка с составными ключами |
Троичные деревья поиска |
|
Поразрядная сортировка |
Боры |
В данном разделе представлены алгоритм и структура данных, фигурирующие в средней строке таблицы. Как в поразрядной сортировке и борах, в троичных деревьях поиска составные ключи исследуются последовательно – поле за полем, от старших полей к младшим. Как в быстрой сортировке и в бинарных деревьях поиска, в троичных деревьях сравниваются отдельные поля, индексы массивов не используются.
Мы выразим задачи в терминах набора
n векторов, размерности k каждый. Базисная операция – троичное сравнение двух компонент векторов. Мунро и Раман [18] описывают алгоритм для сортировки наборов векторов на месте и дают ссылки на предыдущие работы в этой области.В разделе «Составные ключи из слов» Хоар
[9] следующим образом описывает модификацию внутренней сортировки, предложенную Шеклтоном: «Когда известно, что сегмент охватывает те, и только те объекты, у которых значения первых n полей ключа совпадают с первыми n полями заданного значения, то при разбиении этого сегмента сравниваются (n+1)-е слова ключей». Хоар дает неуклюжую реализацию этой элегантной идеи; Кнут [11] представляет подробности схемы Шеклтона в решении 5.2.2.30.Троичный алгоритм разбиения доставляет элегантную реализацию быстрой сортировки Хоара для составных ключей. Нижеследующий рекурсивный псевдокод сортирует последовательность
s длины n, когда известно, что ее компоненты 1..d-1 равны друг другу; самый первый вызов – это, конечно sort(s, n, 1).
sort(s, n, d) if n <= 1 or d > k return; выбрать расщепляющее значение v; разбить s по значению v компоненты с номером d, получив последовательности s<,s=,s> длины которых n<, n=, n>; sort(s<, n<, d); sort(s=, n=, d + 1); sort(s>, n>, d); |
Расщепляющее значение можно выбрать множеством разных способов – от вычисления истинной медианы заданной компоненты до выбора случайного значения компоненты.
Троичные деревья поиска изоморфны этому алгоритму. Каждый узел в этом дереве содержит расщепляющее значение и указатели на потомков с меньшими и большими значениями (или левых и правых); эти поля выполняют ту же роль, что и соответствующие поля в бинарных деревьях поиска. Каждый узел содержит также указатель на поддерево, представляющее набор векторов со значениями, равными расщепляющему. Если данный узел расщепляет по измерению
d, его правые и левые потомки расщепляют по тому же измерению, в то время как поддерево равных расщеплено по измерению d + 1. Как и бинарные деревья поиска, троичные деревья могут быть сбалансированными, построенными вводом элементов в случайном порядке или частично сбалансированными.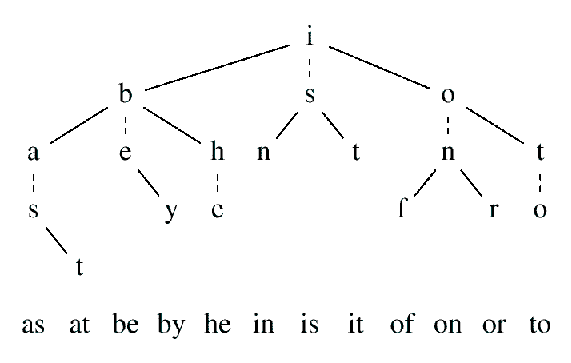
Рис. 2. Троичное дерево поиска для 12 двухбуквенных слов.
В разделе 6.22 Кнут
[11] строит оптимальное бинарное дерево поиска для представления множества из 31 наиболее распространенных английских слов; 12 из них содержат по 2 буквы. На рисунке 2 показано сбалансированное дерево поиска, получающееся в результате рассмотрения этих слов как набора из n = 12 векторов по k = 2 компонент каждый. Указатели к меньшим и большим значениям изображены сплошными линиями, а указатели к равным – пунктирными. Под каждым конечным узлом помещено соответствующее входное слово. Это дерево было построено расщеплением вокруг истинной медианы каждого подмножества.При поиске слова
«is» мы начинаем с корня, спускаемся по поддереву равных к узлу «s», и останавливаемся там после двух сравнений. При поиске «ax» мы делаем три сравнения с первой буквой («a») и два сравнения со второй буквой («x»), затем сообщаем, что такого слова в этом дереве нет.Эта идея относится по крайней мере к 1964; см., например, Клампет
[5]. Предыдущие авторы предлагали представлять поддеревья узла бора в виде массива или связанного списка; Клампет представляет множество поддеревьев бинарным деревом поиска; его структуру уже можно считать троичным деревом поиска. Мелхорн [17] предложил взвешенное сбалансированное троичное дерево поиска, в котором поиск, вставка и удаление элементов в множестве из n строк длины k каждая требует времени O(log n + k); похожая структура описана в разделе III.6.3 работы Мелхорна [16].Бентли и Сакс
[4] рассматривают сбалансированное троичное дерево поиска. Значением каждого узла является медиана множества элементов в подходящем измерении; дерево на рис. 1 было построено таким способом. Бентли и Сакс представляют эту структуру как решение задачи вычислительной геометрии; они выводят его многомерной декомпозицией. Троичные деревья поиска можно построить многими способами, например, вставлять элементы в порядке ввода или строить сбалансированное дерево, считая совокупность элементов полностью заданной. Вайшнави [25] и Слитор с Тарьяном [24] предлагают схемы балансировки троичных деревьев поиска.